
100 其他
项目笔记
- extData: 扩展数据
Total control 手机投屏电脑
## java 各个中间件技术框架
网关:Nginx、Kong、Zuul
缓存:Redis、MemCached、OsCache、EhCache
搜索:ElasticSearch、Solr
熔断:Hystrix、resilience4j
负载均衡:DNS、F5、LVS、Nginx、OpenResty、HAproxy
注册中心:Eureka、Zookeeper、Redis、Etcd、Consul
认证鉴权:JWT
消费队列:RabbitMQ、ZeroMQ、Redis、ActiveMQ、Kafka
系统监控:Grafana、Prometheus、Influxdb、Telegraf、Lepus
文件系统:OSS、NFS、FastDFS、MogileFS
RPC框架: Dubbo、Motan、Thrift、grpc
构建工具:Maven、Gradle
集成部署:Docker、Jenkins、Git、Maven
分布式配置:Disconf、Apollo、Spring Cloud Config、Diamond
压测:LoadRunner、JMeter、AB、webbench
数据库:MySql、Redis、MongoDB、PostgreSQL、Memcache、HBase
网络:专用网络VPC、弹性公网IP、CDN
数据库中间件:DRDS、Mycat、360 Atlas、Cobar (不维护了)
分布式框架:Dubbo、Motan、Spring-Could
分布式任务:XXL-JOB、Elastic-Job、Saturn、Quartz
分布式追踪:Pinpoint、CAT、zipkin
vscode装个插件:live server 可以代码修改后实时更新
https://blog.csdn.net/u012012621/article/details/50998392
打jar https://www.cnblogs.com/qifengshi/p/6036870.html
git 教程 https://www.bilibili.com/video/BV1pW411A7a5?p=58
https://www.bookstack.cn/read/sdky-java-note/3e78ff1a5c3d158d.md
定时器:@Scheduled https://blog.csdn.net/u011374582/article/details/82883620
https://blog.csdn.net/weixin_42753193/article/details/122189782
b站视频下载;https://bilibili.iiilab.com/
接口有HTTP接口、WebService接口、FTP文件传输
gitee 作为图床有个问题,图片大小不能 超过 1M
- 对象存储
- docker部署
技术选型:
- 核心框架:Spring Boot。
- 安全框架:Apache Shiro。
- 模板引擎:Thymeleaf。
- 持久层框架:MyBatis。
- 定时任务:Quartz。
- 数据库连接池:Druid。
- 工具类:Fastjson。
翻墙:https://www.zionladdero.com/
待整理:https://blog.csdn.net/qq_33683097/article/details/81230111 ssm maven 工程目录以及环境搭建(对配置文件的介绍)
整理代表:ydxjApply 巡检保人事申请
接口开发:https://blog.csdn.net/diyangxia/article/details/64122387
https://oss.console.aliyun.com/bucket/oss-cn-shanghai/lishihuan/object?path=20210408%2F
https://blog.csdn.net/vivivi_lau/article/details/106501715
git: https://git-scm.com/book/zh/v2
图形化工具:Source Tree,[TortoiseGit](# https://www.cnblogs.com/xiuxingzhe/p/9312929.html)
https://www.cnblogs.com/tugenhua0707/p/4050072.html
js 实现 复制图片到剪切板 https://blog.csdn.net/MICHAELKING1/article/details/89642497
js 模板:https://blog.csdn.net/qq_42943107/article/details/91045524
css 动画;https://zh.javascript.info/css-animations#guan-jian-zhen-dong-hua-keyframes
css 实现 图文切换:https://www.cnblogs.com/cs-whut/p/13463928.html (C:\Users\lishihuan\Desktop\html动画-待整理\CSS动画实例:图文切换.html)
layer 弹窗层 https://blog.csdn.net/qq_37335220/article/details/82024066
图片 都放到一起,通过定位来 显示 当中的 具体 图片,例如ztree 图标 (用到属性 background-position)
Collections3.extractToString 对 集合的处理
使用 Fiddler 实现本地代码替换远程代码 https://zhangzw.com/posts/20190501.html
idea 设置svn代码忽略:https://blog.csdn.net/idongit/article/details/103079171
https://tool.lu/tinyimage/ 在线压缩图片
java 待整理: ControllerAdvice 注解
测试图片:https://gitee.com/mylishihuan/image/raw/master/img/20201115092508.jpg
引入 jQuery 库
<script src="http://code.jquery.com/jquery-1.11.3.min.js"></script> <script src="http://www.jq22.com/jquery/1.11.1/jquery.min.js"></script>
待整理 盒子模型:https://www.cnblogs.com/hellocd/p/10443237.html
待整理: js 闭包 https://blog.csdn.net/weixin_39214481/article/details/86164785
待整理-java 导出word:https://www.jianshu.com/p/de58ab550157
https://blog.csdn.net/xm393392625/article/details/88795547 插入图片
var data = eval('('+evt.data+')');
JSON.parse(itemStr);
跨域:https://blog.csdn.net/qq_30546099/article/details/71404574
不同域名之间共享localStorage/sessionStorage https://www.jianshu.com/p/8c4cee29d532 (解决跨域场景)
netty websocket实现心跳和断线重连
https://www.cnblogs.com/chaizezhao/articles/5291608.html
app开发;https://blog.csdn.net/lucy_100/article/details/49820393
待整理,CPMS 组织树 (TreeBean)
整理 图片放大器:<div ng-include="'modules/sys/picGiger.html'"></div> 如何实现 作为公共 模块的
待整理:坐标转换(java,js) 坐标获取位置信息
Notepad++ 临时备份文件路径: C:\Users\lishihuan\AppData\Roaming\Notepad++\backup\
全景图 photo-sphere-viewer : https://www.jianshu.com/p/78208c73a896https://photo-sphere-viewer.js.org/ 2D:https://blog.csdn.net/haiwei_lian/article/details/109012683
J2Cache缓存:https://gitee.com/ld/J2Cache
快捷键:
https://blog.csdn.net/ademoa/article/details/80091939
Idea:
ctrl+shift+x 转为大写
ctrl+shift+y 转为小写
sql 美化器:ctrl+alt+
Ctrl+alt+v 补全等号左侧
Alt+Ctrl+T 快速 tyr/catch (选中代码后也可以使用快捷键,Alt+Shift+Z 快速tyr/catch)
new XXX(); @ + L 自动生成new的新对象
Ctrl +shift+ o 批量引出jar包和删除多余jar包
for 循环 补全 https://blog.csdn.net/weixin_41637749/article/details/83784570 https://blog.csdn.net/mingjie1212/article/details/51143444
收起展开所有方法的快捷键( Ctrl+Shift+'/'(小键盘的‘/‘) Ctrl+alt+= 递归展开当前方法 )
- 全部展开、折叠:Ctrl+Shift+”+/-”,
- 展开、折叠当前方法:Ctrl + " +/- "
- 小写转换大写 Ctrl + shift + U
- 大写转换小写Ctrl + U
- 复制当前行 Ctrl + D
- 删除当前行 Ctrl +L (相当于剪切 + 删除行,并不是存粹的删除行)
ctrl+q 可以查看方法具体在哪个包里面,或是jar包
- ctrl+alt+o 去掉没有引用的import
- ctrl+alt+B 查看接口被哪些类实现
- ctrl+shift+alt+u 查看类的继承关系
- ctrl+alt+u 查看类的继承关系
- ctrl+shift+u 代码中大小写切换
- ctrl+O 选择父类方法去重写,这里没有继承直接显示继承自Object类的方法
MyEclipse :
- Alt+Shift+L 代码等号右边自动补全
- 收起展开所有方法的快捷键
- 收缩所有方法:Ctrl+Shift+'/'(小键盘的‘/‘)
- 展开所有方法:Ctrl+Shift+'*'(小键盘的)
输入法英文间距太大 (全角和半角) shift+空格
常用次:扁平化,存量,增量
坐标系
公司:
谷歌地图:31.9344120986,117.2649120808 ----> 和 腾讯和高德坐标偏移很小
百度地图:31.9405040000,117.2714210000
腾讯高德:31.9344119085,117.2649256012
图吧地图:31.9378224285,117.2620342812
谷歌地球:31.9364424285,117.2594242812 ---> 现在市面上 GPS都是用这个的
北纬N31°56′11.19″ 东经E117°15′33.93″
坐标系说明
WGS84坐标系 地球坐标系,国际通用坐标系 ---GPS
GCJ02坐标系 火星坐标系,WGS84坐标系加密后的坐标系;Google国内地图、高德、QQ地图、腾讯地图 使用
BD09坐标系 百度坐标系,GCJ02坐标系加密后的坐标系
注:
谷歌地图API,高德地图API,腾讯地图API上取到的,都是GCJ-02坐标,他们三家都是通用的
百度:BD-09坐标
谷歌地球,google earth上取到的,是GPS坐标。而且是度分秒形式的经纬度坐标。在国内不允许使用。必须转换为GCJ-02坐标
数据库
数据库连接失败,navicat可以连接上,但是java程序无法连接 useSSL=false
11 oracle
plsql 中 ctrl+e 查看 历史执行的语句
shu据库:https://192.168.99.19:1158/em
11.1
命令运行 : sqlplus /nolog
给system赋权 :grant sysdba to system;
sql文件导入导致plsql 等工具卡死,无法执行解决:
1.cmd-->输入: conn sys/as sysdba
2.输入密码 lishihuan
3. sql>@'D:\aa.sql'; 执行后导入sql文件
oracle em 主机身份证明 输入的用户名和密码是 电脑端的,比如我的是 wangyilishihuna@163.com e9q......
cmd 执行 sql 命令
sqlplus /nolog
conn /as sysdba
11.1oracle 一些常用 语句
数据库创建一个用户
/*(命令行运行: sqlplus /nolog 在SQL>提示符后面运行: conn /as sysdba 命令横提示Connected说明连接成功;)*/
--1.查询用户 (检查用户对象,导库的时候可以用来检测,目标用户是否存在)
select * from dba_users;
--2.查询表控件本地存储位置
select name from v$datafile;
--3.创建表空间
create tablespace sdt_tyxxpt datafile 'D:\ORACLE\ORADATA\ORCL\sdt_tyxxpt.dbf' size 50m autoextend on next 50m maxsize 20480m extent management local;
--说明:(create tablespace 表空间名称 datafile '数据文件的路径' size 大小 autoextend on ; (autoextend 自增长)命令行输入)
--4.创建用户: 创建用户语法:create user 用户名 identified by 密码 default tablespace 用户默认使用哪一个表空间;
create user sdt_tyxxpt identified by sdt_tyxxpt default tablespace sdt_tyxxpt temporary tablespace temp;
--5.给用户授予权限
grant connect,resource,dba to sdt_tyxxpt;
--6.删除 (https://blog.csdn.net/dongyuxu342719/article/details/81530942)
--删除用户
drop user 用户名称 cascade;
--删除表空间(同时也会删除本地存储 的dmp文件)
drop tablespace 表空间名称 including contents and datafiles cascade constraint;
-- 7.修改用户密码
alter user SDT_XJB identified by SDT_XJB;
--8.数据库em
https://localhost:1158/em;
删除用户失败,提示 ORA-01940 用户被使用在,所以需要先杀死进程
select username,sid,serial#,paddr from v$session where username='INVOICE'; alter system kill session '62,22594';

修改用户密码
alter user 用户名 identified by 新密码;
查询每个表的 数据量
select u.TABLE_NAME,u.NUM_ROWS from user_tables u order by u.NUM_ROWS desc
查看ORACLE表空间大小及所剩空间大小 (单位MB)
select a.tablespace_name,
a.bytes / 1024 / 1024 "Sum MB",
(a.bytes - b.bytes) / 1024 / 1024 "used MB",
b.bytes / 1024 / 1024 "free MB",
round(((a.bytes - b.bytes) / a.bytes) * 100, 2) "percent_used"
from (select tablespace_name, sum(bytes) bytes
from dba_data_files
group by tablespace_name) a,
(select tablespace_name, sum(bytes) bytes, max(bytes) largest
from dba_free_space
group by tablespace_name) b
where a.tablespace_name = b.tablespace_name
order by ((a.bytes - b.bytes) / a.bytes) desc;
SELECT UPPER(F.TABLESPACE_NAME) "表空间名",
D.TOT_GROOTTE_MB "表空间大小(M)",
D.TOT_GROOTTE_MB - F.TOTAL_BYTES "已使用空间(M)",
TO_CHAR(ROUND((D.TOT_GROOTTE_MB - F.TOTAL_BYTES) / D.TOT_GROOTTE_MB * 100, 2),'990.99') "使用比",
F.TOTAL_BYTES "空闲空间(M)",
F.MAX_BYTES "最大块(M)"
FROM (SELECT TABLESPACE_NAME,
ROUND(SUM(BYTES) / (1024 * 1024), 2) TOTAL_BYTES,
ROUND(MAX(BYTES) / (1024 * 1024), 2) MAX_BYTES
FROM SYS.DBA_FREE_SPACE
GROUP BY TABLESPACE_NAME) F,
(SELECT DD.TABLESPACE_NAME,
ROUND(SUM(DD.BYTES) / (1024 * 1024), 2) TOT_GROOTTE_MB
FROM SYS.DBA_DATA_FILES DD
GROUP BY DD.TABLESPACE_NAME) D
WHERE D.TABLESPACE_NAME = F.TABLESPACE_NAME
ORDER BY 4 DESC;
查询表空间
SELECT owner,t.table_name,
num_rows, --记录行数
s.bytes / 1024 / 1024 AS size_mb
FROM all_tables t
JOIN user_segments s ON t.table_name = s.segment_name
WHERE s.segment_type = 'TABLE'
AND t.owner = 'SDT_ZHST_2024' -- 目标用户
ORDER BY size_mb DESC;
查询大表,并且释放表空间
- 最优的是 通过
DROP TABLE table_name;CREATE TABLE table_name (...);-- 重新创建表- 通过 delete 删除后,不会自动释放空间,需要 可以 使用
SHRINK SPACE命令
-- 启用行移动: 使用以下命令来启用表的行移动:
ALTER TABLE SYS_LOG ENABLE ROW MOVEMENT;
-- 行空间压缩操作: 启用行移动后,你可以执行 SHRINK SPACE 或 MOVE 操作来释放空间
ALTER TABLE SYS_LOG SHRINK SPACE;
ALTER TABLE SYS_LOG MOVE;
-- 禁用行移动(可选): 如果你完成了所需的操作,并且希望禁用行移动,可以执行以下命令
ALTER TABLE SYS_LOG DISABLE ROW MOVEMENT;
查询用户下的所有表
select t.* from user_tables t;
select * from all_tab_comments;--查询所有用户的表,视图等。
select * from user_tab_comments;--查询本用户的表,视图等。
select * from all_col_comments;--查询所有用户的表的列名和注释。
select * from user_col_comments;--查询本用户的表的列名和注释。
select * from all_tab_columns;--查询所有用户的表的列名等信息。
select * from user_tab_columns;--查询本用户的表的列名等信息。
/*
ORACLE下有三个视图
DBA_TABLES 拥有DBA角色的用户可以查看系统中的所有表
USER_TABLES 登录数据库的当前用户拥有的所有表
ALL_TABLES 登录数据库的当前用户有权限查看的所有表
*/
查询空表
select * from user_tables where num_rows=0;
select username,default_tablespace from user_users;-- 查询当前用户下的表空间
select name from v$datafile;-- 查询表空间的位置
SELECT FILE_NAME,TABLESPACE_NAME,AUTOEXTENSIBLE FROM dba_data_files; -- 查看表空间是否自增长
修改表空间
-- 如果是 迁移表,针对需要 修改表空间的场景,需要 分2步,1.修改表的 表空间 2.重建 索引 的 表空间
---- 1.讲表 ACT_RU_JOB 的表空间修改为 SDT_XJB
alter table ACT_RU_JOB move tablespace SDT_XJB;
---- 2. 重建 索引
select 'alter index '||index_name||' rebuild online;' from user_indexes
where status <> 'VALID' and index_name not like'%$$' or tablespace_name ='SDT_IMOA';;
----- 本质执行 alter index 索引名称 rebuild online; 重建
-- 查询索引(用于检查是否有些 重构 索引 但是没有 讲表空间修改 好)
select tablespace_name,index_name,t.table_name,t.status from SYS.USER_INDEXES t;--(USER_INDEXES 查询索引信息的视图)
--批量修改(找到 索引 表空间为 SDT_IMOA 的所有索引 修改语句,将其 修改为 CPMS)
select 'alter index '||index_name||' rebuild tablespace CPMS;' from user_indexes where tablespace_name ='SDT_IMOA';
--alter index 索引名称 rebuild online; --重建
--alter index 索引名称 rebuild tablespace 表空间; --修改表空间
增加表空间
-- 1. 创建表空间
create tablespace SDT_XJB datafile 'D:\app\Administrator\oradata\orcl\SDT_XJB02.DBF' size 1024m autoextend on next 50m maxsize 20480m extent management local;
-- 2.增加表空间文件-针对表空间不够
alter tablespace SDT_XJB add datafile 'D:\app\Administrator\oradata\orcl\SDT_XJB02.DBF' size 30720M AUTOEXTEND on next 100m;
拼接语句查询出所有表要迁入表空间的语句,这样可以批量查询出来,修改方便。
select 'alter table '|| table_name ||' move tablespace 要迁入的表空间;' from dba_tables t where t.owner='要迁出的表归属用户名';
查询出指定表空间下的表:
select tablespace_name,table_name from user_tables WHERE tablespace_name='表空间名称';
查询出单一表对应的表空间:
select tablespace_name,table_name from user_tables where table_name='表名';
复制表,迁移表
注: 这样用于 迁移表 比 exp和imp 导出方便,如果两个数据库不在一起,可以通过建立 dblink
-- 迁移 同数据库,不同 用户下的 接地线表,即 讲 SDT_IMOA用户下的巡检保表 迁移到 巡检保下
select
'create table '|| table_name ||' as select * from SDT_IMOA.'|| table_name ||';'
from user_tables where table_name like 'JDX_%';
获取 DDL 语句
SELECT DBMS_METADATA.GET_DDL('TABLE',u.table_name) FROM USER_TABLES u;
SELECT DBMS_METADATA.GET_DDL('INDEX',u.index_name) FROM USER_INDEXES u;
查询每个表数量
select t.table_name,t.num_rows from user_tables t;
主键、唯一性约束 、联合主键
对于除了主键还需要 其他字段做唯一性约束,(例如部门下管的行政区域,那么中间表需要 部门和行政区域合再一起做唯一性约束)
alter table zcz add constraints zcz_pk primary key (id); -- 主键
alter table zcz add constraints zcz_name_age primary key (name,age);--联合主键
--创建联合约束(下面该条sql的作用是name和age不能同时相等)
CREATE UNIQUE INDEX zcz_name_age ON zcz(NVL2(name,age,NULL),NVL2(name,name,NULL));
-- 创建unique唯一约束(不能存在 name+age相同的数据)
alter table table_name add constraint name_age_unique unique(name,age));
-- 给表添加 主键和联合约束
alter table BAS_C_LINE_RELEVANCE
add constraints PK_BAS_C_LINE_RELEVANCE primary key (id)
add constraint ID_PID_UNIQUE unique(LINE_PID,LINE_ID);
查询库中的表名和表中记录数
SELECT T.TABLE_NAME, T.NUM_ROWS FROM USER_TABLES T;
表数据被删除,但是空间没被释放
truncate table YDXJ_DW_DWJL_2018_08 DROP STORAGE;
alter TABLE YDXJ_DW_DWJL_2018_08 deallocate unused keep 1k;
导入时报:ora-01659 表空间自增长的原因
select name from v$datafile;
alter database datafile 'D:\APP\LISHIHUAN\ORADATA\ORCL\SDT_XJB.DBF' autoextend on;
#### 创建表:
create table 表名 (
字段名1 字段类型 默认值 是否为空 ,
字段名2 字段类型 默认值 是否为空,
字段名3 字段类型 默认值 是否为空,
......
);
demo 创建一个user表:
create table user (
id number(6) primary key, ---主键
name varchar(50) not null, ---姓名 不为null
sex varchar2(6) default '男' check ( sex in ('男','女')) ---性别 默认'男'
);
create table 表名 ( 字段名1 字段类型 默认值 是否为空 , 字段名2 字段类型 默认值 是否为空, 字段名3 字段类型 默认值 是否为空, ...... ); demo 创建一个user表:
修改表名:
rename 旧表名 to 新表名;
rename user to newuser;
删除表
delete from 表名;
delete删除数据是一条一条的删除数据,后面可以添加where条件,不删除表结构。注意:如果表中有identity产生的自增id列,delete from后仍然从上次的数开始增加。
truncate table 表名;
truncate是一次性删掉所有数据,不删除表结构。注意:如果表中有identity产生的自增id列,truncate后,会恢复初始值。
drop table 表名;
drop删除所有数据,会删除表结构。
修改表
- 添加新字段:
alter table 表名 add(字段名 字段类型 默认值 是否为空);
alter table user add(age number(6));
alter table user add (course varchar2(30) default '空' not null);
## 添加备注
comment on column SYS_PUSH_CONTENT.meta_info is '存储非格式化数据(用于针对不同消息展示的不同消息内容的情况)';
- 修改字段:
alter table 表名 modify (字段名 字段类型 默认值 是否为空);
alter table user modify((age number(8));
- 修改字段名:
alter table 表名 rename column 列名 to 新列名;
alter table user rename column course to newcourse;
- 删除字段:
--1、从表中随机取记录
select * from (select * from staff order by dbms_random.random) where rownum < 4 --表示从STAFF表中随机取3条记录
--2、产生随机数
SELECT DBMS_RANDOM.RANDOM FROM DUAL; --产生一个任意大小的随机数
SELECT ABS(MOD(DBMS_RANDOM.RANDOM,100)) FROM DUAL; --产生一个100以内的随机数
SELECT TRUNC(100+900*dbms_random.value) FROM dual; --产生一个100~1000之间的随机数
SELECT dbms_random.value FROM dual; --产生一个0~1之间的随机数
SELECT dbms_random.value(10,20) FROM dual; --产生一个10~20之间的随机数
SELECT dbms_random.normal FROM dual; --NORMAL函数返回服从正态分布的一组数。此正态分布标准偏差为1,期望值为0。这个函数返回的数值中有68%是介于-1与+1之间,95%介于-2与+2之间,99%介于-3与+3之间。
--3、产生随机字符串
select dbms_random.string('P',20) from dual; --第一个参数 P 表示 printable,即字符串由任意可打印字符构成 第二个参数表示返回字符串长度
--4、ceil( n )函数是返回大于或等于n的最小整数。
/*
DBMS_RANDOM.VALUE()是随机产生( 0,1 )之间的数。要产生两位的随机数,可以DBMS_RANDOM.VALUE()*100,这样产生( 0,100 )的随机数,当产生( 0,10)之间的数时,只要加上10就可以保证产生的数都是两位了。
*/
--ORACLE的PL/SQL提供了生成随机数和随机字符串的多种方式,罗列如下:
--1、小数( 0 ~ 1)
select dbms_random.value from dual;
--2、指定范围内的小数 ( 0 ~ 100 )
select dbms_random.value(0,100) from dual
--3、指定范围内的整数 ( 0 ~ 100 )
select trunc(dbms_random.value(0,100)) from dual
--4、长度为20的随机数字串
select substr(cast(dbms_random.value as varchar2(38)),3,20) from dual
--5、正态分布的随机数
select dbms_random.normal from dual
--6、随机字符串
select dbms_random.string(opt, length) from dual
--opt可取值如下: 'u','U' : 大写字母 'l','L' : 小写字母 'a','A' : 大、小写字母 'x','X' : 数字、大写字母 'p','P' : 可打印字符
--7、随机日期
select to_date(2454084+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J') from dual
通过下面的语句获得指定日期的基数
select to_char(sysdate,'J') from dual
--8、生成GUID
select sys_guid() from dual
--生成带分隔符(-)的GUID的自定义函数
create or replace function my_guid return varchar2 is guid varchar(36); temp varchar(32); begin temp:=sys_guid(); guid:= substr(temp,1,8) || '-' ||substr(temp,9,4) || '-' ||substr(temp,13,4)|| '-' ||substr(temp,17,4)|| '-' ||substr(temp,21,12); return guid; end;
修改表空间
已 表空间为 SDT_YJWZ_TEMP 这个为例: 将 表空间不是 SDT_YJWZ_TEMP 改为 SDT_YJWZ_TEMP
- 单个表修改表空间
ALTER TABLE SDT_YJWZ_TEMP.表名
MOVE TABLESPACE SDT_YJWZ_TEMP;
-- 生成索引重建 SQL
ALTER INDEX SDT_YJWZ_TEMP.索引名
REBUILD TABLESPACE SDT_YJWZ_TEMP;
- 批量修改
SELECT
'ALTER TABLE ' || owner || '.' || table_name ||
' MOVE TABLESPACE SDT_YJWZ_TEMP;'
FROM dba_tables
WHERE owner = 'SDT_YJWZ_TEMP'
AND tablespace_name <> 'SDT_YJWZ_TEMP';
-- 生成索引重建 SQL
SELECT
'ALTER INDEX ' || owner || '.' || index_name ||
' REBUILD TABLESPACE SDT_YJWZ_TEMP;'
FROM dba_indexes
WHERE owner = 'SDT_YJWZ_TEMP'
AND tablespace_name <> 'SDT_YJWZ_TEMP';
LOB 字段怎么办?(很多人踩坑)
如果表里有
CLOB / BLOB,只 MOVE 表是不够的
-- 查 LOB
SELECT table_name, column_name, tablespace_name
FROM dba_lobs
WHERE owner='SDT_YJWZ_TEMP'
AND tablespace_name <> 'SDT_YJWZ_TEMP';
-- 移动 LOB
ALTER TABLE SDT_YJWZ_TEMP.表名
MOVE LOB(列名) STORE AS (TABLESPACE SDT_YJWZ_TEMP);
11.2 数据库导入,导出
- 导出/导入的时候考虑到用户下的表可能存在多个表空间,导致数据迁移存在异常,所以可以先查询表所涉及到的表空间,然后导入的时候合并一下
SELECT table_name, tablespace_name
FROM all_tables
WHERE owner = '用户名';
exp 导出 imp 导入
遇到密码特殊字符 使用3个双引号
exp sdt_xjb/"""Ahsbd@2021yjfgs"""@172.16.10.247:1521/yjdb file=D:\temp\ydxj_dundian_20211118.dmp tables=(xjb_dundian_%)
exp 导出 imp 导入 (EXP和IMP是客户端工具程序,它们既可以在客户端使用,也可以在服务端使用。EXP不会导出空表,可能会对存储过程有影响)
1.导出:exp sdt_imoa/sdt_imoa@192.168.10.228/yjdb2 file=d:\sdt_imoa_20180831.dmp tables=(ydxj_dundian_%) rows=n
说明: 1.sdt_imoa/sdt_imoa 是用户名和密码
2.@192.168.10.228/yjdb2 对应连接数据库时的路径192.168.10.229:1521/yjdb
3.tables=(BAS_TOWER_%,BAS_FROMPART_TYPE,BAS_TYPEFROM_REF) 指定导出表,支持模糊匹配
4.rows=n 表示只要表结构,不要数据
案例:将数据库中system用户与sys用户的表导出
exp system/manager@TEST file=d:\daochu.dmp owner=(system,sys)
案例:将数据库中的表table1中的字段filed1以"00"打头的数据导出
exp system/manager@TEST file=d:\daochu.dmp tables=(table1) query=\" where filed1 like '00%'\"
2.导入: imp sdt_tyxxpt/sdt_tyxxpt@61.191.56.150:1521/xjb file=f:\sdt_imoa2018-08-31.dmp full=y data_only=y log=E:\20191127.log ;
说明:1.rows=n 只导表结构
2.data_only=y 只导数据
3.ignore=y只导入数据,不导入表结构(没有的表,创建并倒入数据,如果已经有的表,忽略创建的,但不忽略倒入)
4. 日志输出 log
案例: 将d:\daochu.dmp中的表table1 导入
imp system/manager@TEST file=d:\daochu.dmp tables=(table1)
如果导入的表空间不同,导入数据会报错,那么可以先只导入表结构,然后通过imp 导入表数据
3.指定表空间导入,没测试过(针对全数据库导出,先需要导出特定的用户,fromuser=用户)
imp CPMS_INVO/CPMS_INVO@36.7.176.72:11521/xjb fromuser=invoice touser=CPMS_INVO file=E:\invo_20191127.dmp log=E:\20191127.log
fromuser指定dmp文件中要导出的用户,touser 准备导入表的 数据用户
存在问题
EXP不会导出空表,可能会对存储过程有影响 https://www.2cto.com/database/201703/615378.htmlhttps://blog.csdn.net/whxlovexue/article/details/82378389
可能会出现提示表空间不存在,也即是讲当前创建的用户和exp导出的不一致,只能新增一个表空间来解决,获取用
EXPDP和IMPDP可以指定
--1.在建好数据库后执行如下脚本:
alter system set deferred_segment_creation=false;
--2:批量执行空表更新语句
--A: 查询当前用户下的所有记录数为空的表
select TABLE_NAME from user_tables t where t.NUM_ROWS = 0 or t.NUM_ROWS is null;
--B:生成修改语句,将SEGMENT_CREATED 修改为YES
select 'alter table '||table_name||' allocate extent;' from user_tables t where t.NUM_ROWS = 0 or t.NUM_ROWS is null;
--参考网址:https://blog.csdn.net/whxlovexue/article/details/82378389
imp/impdp 和 EXPDP和IMPDP时应该注意的事项:
- EXP和IMP是客户端工具程序,它们既可以在客户端使用,也可以在服务端使用。
- EXPDP和IMPDP是服务端的工具程序,他们只能在ORACLE服务端使用,不能在客户端使用。
- IMP只适用于EXP导出的文件,不适用于EXPDP导出文件;IMPDP只适用于EXPDP导出的文件,而不适用于EXP导出文件。
数据泵:expdp/impdp导出/导入数据
数据库恢复(导入):需要将之前的数据库清除,因为不能覆盖恢复,所以会导出失败
数据泵:expdp/impdp导出/导入数据
https://www.cnblogs.com/wanghongyun/p/6307652.html
使用impdp命令,需要在oracle数据库服务器操作:
1.使用sqlplus或者Oracle客户端(PL/SQL) 链接到相应的Oracle数据库实例(进行下面第一,第二两步骤的操作)
一、创建逻辑目录,该命令不会在操作系统创建真正的目录,最好以system等管理员创建。
创建:create directory dpdata1 as 'd:\temp';
修改:create or replace directory dpdata1 as 'E:\temp';
删除:drop directory dpdata1;
(查看服务器上若没有存在d:\temp目录,则手动新建,把dmp备份文件放到d:\temp目录下面)
二、查看管理理员目录(同时查看操作系统是否存在,因为Oracle并不关心该目录是否存在,如果不存在,则出错)
select * from dba_directories;
2.导入数据库(桌面下执行cmd--然后命令)
--expdp导出数据
expdp CCENSE/CCENSE@OracleDB directory = "dpdata1" dumpfile ="oracleExpdp.dmp" logfile = oracleExpdp20161103.log
expdp CCENSE/CCENSE@OracleDB directory = "dpdata1" dumpfile ="oracleExpdp.dmp" logfile = oracleExpdp20161103.log schemas=SDT_IMOA tablespaces=YOUR_TABLESPACE_NAME
/*
* schemas=SDT_IMOA 指定导出用户
* tablespaces=YOUR_TABLESPACE_NAME 指定导出表空间
*/
--impdp导入数据
impdp CCENSE/CCENSE@OracleDB directory="dpdata1" dumpfile="oracleExpdp.dmp" logfile = oracleImpdp20161103.log FULL=y;
/* 说明:CCENSE/CCENSE@OracleDB --->用户名/密码@数据库实例
directory="在步骤一中创建的逻辑目录"
dumpfile="需要导入/导出的dmp文件全称"
logfile="日志文件"
tables=xxx,xxx 指定导出表
FULL=y;
针对密码存在特殊字符的 expdp sdt_imoa/"""sdt_zhst@Ahsbd"""@xxx/yjdb
注意: 如果 目标用户和导出的用户不一致,一定要 通过REMAP_SCHEMA去指定,如: REMAP_SCHEMA=CPMS:CPMS_0309 如果不指定,则导入的数据会自动创建CPMS_0309 而不是希望的 CPMS用户中
*/
impdp CPMS_0309/CPMS_0309@127.0.0.1:1521/orcl directory = dpdata1 dumpfile =CPMS_0309.dmp logfile = CPMS_0309.log REMAP_SCHEMA=CPMS:CPMS_0309 remap_tablespace=CPMS:CPMS_0309
-- 讲CPMS正式数据库的表导入到 CPMS_0309用户下,impdp可以指定 需要导入的表空间和用户
REMAP_SCHEMA=CPMS:CPMS_0309 表示 由原来的 CPMS用户导入到CPMS_0309用户下, remap_tablespace=CPMS:CPMS_0309表示 由原来的CPMS表空间导入到CPMS_0309表空间下 可以多个
但是 可能存在 告警CPMS.xxx 表存在的问题,可以添加 TABLE_EXISTS_ACTION=REPLACE 【用了REMAP_SCHEMA=CPMS:CPMS_0309 这个不应该会出现这个告警】
impdp ... REMAP_SCHEMA=CPMS:CPMS_0309 remap_tablespace=CPMS:CPMS_0309 TABLE_EXISTS_ACTION=REPLACE
--其他SQL
--表空间[10G]和临时表空间[1G]
/*表空间*/
SELECT t.tablespace_name, round(SUM(bytes / (1024 * 1024)), 0) ts_size
FROM dba_tablespaces t, dba_data_files d
WHERE t.tablespace_name = d.tablespace_name
GROUP BY t.tablespace_name;
/*临时表空间*/
select tablespace_name,file_name,bytes/1024/1024 file_size,autoextensible from dba_temp_files;
-- 查看端口是否被占用
netstat -aon|findstr "1522"
-- 查看监听状态,启动监听,关闭监听
lsnrctl status LISTENER2
lsnrctl start LISTENER2
lsnrctl stop LISTENER2
--访问地址
linux sqlplus ccense/ccense@//localhost:1521/OracleDB;
win sqlplus ccense/ccense@IP:1521/OracleDB;
expdp流程

一、新建逻辑目录
最好以system等管理员创建逻辑目录,Oracle不会自动创建实际的物理目录“D:\oracleData”(务必手动创建此目录),仅仅是进行定义逻辑路径dump_dir;###
忘记sys用户密码的可以去下如何修改sys用户密码;建议使用pl、navicat等oracle操作工具来操作;
登陆后sql执行:create directory mydata as '逻辑目录路径'; 例如:
create directory mydata as '/data/oracle/oradata/mydata';
二、查看逻辑目录是否创建成功
执行sql:
select * from dba_directories

三、用expdp导出数据 用法及解释:
expdp 用户名/密码@ip地址/实例 [属性]
ip地址不写默认就是本地 userid=test/test --导出的用户,本地用户!! directory=dmpfile --导出的逻辑目录,一定要在oracle中创建完成的,并且给用户授权读写权限 dumpfile=xx.dmp --导出的数据文件的名称,如果想在指定的位置的话可以写成dumpfile=/home/oracle/userxx.dmp logfile=xx.log --日志文件,如果不写这个参数的话默认名称就是export.log,可以在本地的文件夹中找到 schemas=userxx --使用dblink导出的用户不是本地的用户,需要加上schema来确定导出的用户,类似于exp中的owner,但还有一定的区别 EXCLUDE=TABLE:"IN('T1','T2','T3')" --exclude 可以指定不导出的东西,table,index等,后面加上不想导出的表名 network_link=db_local --这个参数是使用的dblink来远程导出,需要指定dblink的名称
列出一些场景:
--1)导出用户及其对象
expdp scott/tiger@orcl schemas=scott dumpfile=expdp.dmp directory=dump_dir logfile=expdp.log;
--2)导出指定表
expdp scott/tiger@orcl tables=emp,dept dumpfile=expdp.dmp directory=dump_dir logfile=expdp.log;
--3)按查询条件导
expdp scott/tiger@orcl directory=dump_dir dumpfile=expdp.dmp tables=empquery='where deptno=20' logfile=expdp.log;
--4)按表空间导
expdp system/manager@orcl directory=dump_dir dumpfile=tablespace.dmp tablespaces=temp,example logfile=expdp.log;
--5)导整个数据库
expdp scott/123@127.0.0.1/orcl directory=dump_dir dumpfile=ly.dmp full=y logfile=expdp.log;
一般用的都是导出整个数据库
--包含所有用户的表、视图、索引等
expdp JCPT/123@127.0.0.1/orcl directory=mydata dumpfile=ly.dmp full=y logfile=expdp.log;
--指定用户的表、视图、索引等
expdp JCPT/123@127.0.0.1/orcl directory=mydata schemas=jcpt dumpfile=ly.dmp logfile=expdp.log;--
导出完成后:逻辑目录生成了一个 dmp文件;
IMPDP数据导入
在正式导入数据前,要先确保要导入的用户已存在,如果没有存在,请先用下述命令进行新建用户
流程:

一、创建表空间
使用system登录oracle,执行sql
格式: create tablespace 表间名 datafile '数据文件名' size 表空间大小
create tablespace data_test datafile 'e:\oracle\oradata\test\test.dbf' size 2000M;
-- 数据文件名 包含全路径, 表空间大小 2000M 表是 2000兆
二、创建用户并授权
格式: create user 用户名 identified by 密码 default tablespace 表空间表;
create user study identified by study default tablespace data_test;
-- 我们创建一个用户名为 study,密码为 study, 表空间为 madate-这是在上一步建好的
授权给 用户 study ,执行sql
#给用户逻辑目录读写权限
sql>grant read,write on directory mydata to study;
#给用户表空间权限
sql>grant dba,resource,unlimited tablespace to study;
三、impdp导入
命令在cmd或者控制台输入,不是sql语句
写法:
impdp 用户名/密码@ip地址/实例 [属性]
ip地址不写默认就是本地
注释:
-- 1)导入用户(从用户scott导入到用户scott)
impdp scott/tiger@orcl directory=dump_dir dumpfile=expdp.dmp schemas=scott logfile=impdp.log;
-- 2)导入表(从scott用户中把表dept和emp导入到system用户中)
impdp system/manager@orcl directory=dump_dir dumpfile=expdp.dmp tables=scott.dept,scott.emp remap_schema=scott:system logfile=impdp.log table_exists_action=replace (表空间已存在则替换);
-- 3)导入表空间
impdp system/manager@orcl directory=dump_dir dumpfile=tablespace.dmp tablespaces=example logfile=impdp.log;
-- 4)导入整个数据库
impdb system/manager@orcl directory=dump_dir dumpfile=full.dmp full=y logfile=impdp.log;
-- 5)追加数据
impdp system/manager@orcl directory=dump_dir dumpfile=expdp.dmp schemas=systemtable_exists_action logfile=impdp.log;
日常使用的:
把用户jcpt中所有的表导入到lyxt用户下
impdp lyxt/lyxt123@127.0.0.1/orcl directory=mydata dumpfile=LY.DMP remap_schema=jcpt:lyxt logfile=ims20171122.log table_exists_action=replace
11.10 数据误删
表中数据误删数据
场景: 现有 material_info 表 一条数据 被删除,知道大概的时间和关键字段 ‘攀登自锁器’
select * from material_info as of timestamp to_timestamp('2021-10-28 15:30:00', 'yyyy-mm-dd hh24:mi:ss')
where material_name like '%攀登自锁器%'
to_timestamp: 删除数据的大概时间 ,material_name 是表中字段,用来筛选数据的
表误删
11.52 数据库备份单个表
关键字 复制表、备份表
create table WORK_TASK_LIST__GROUNDWIRE_6 as select * from WORK_TASK_LIST__GROUNDWIRE;
create table myTable_tmpe as select * from myTable where 1=2;-- 只备份表结构,不复制表数据
create table sys_emp_1 as select * from sys_emp@xjbdblink;-- 使用dblink
11.53 oracle常用 函数
- replace 替换
select replace('123123tech', '123') from dual; --返回 'tech'============将 字符串 123123tech中123 去掉 最终结果是tech
select replace('123tech123', '123') from dual; --返回 'tech'
select replace('222tech', '2', '3') from dual; --返回 '333tech'============将字符串 222tech 中的2 替换为 3 最终结果是 333tech
select replace('0000123', '0') from dual; --返回 '123'
select replace('0000123', '0', ' ') from dual; --返回 ' 123'
- 截取 SUBSTR & INSTR
案例:截取 人员头像中的图片名称
select name,photo,substr(photo,instr(photo, '/',-1)+1),id from SYS_USER t where t.del_flag=0;
| 名称 | 头像路径 | 被截取文件名称 |
|---|---|---|
| aa | /userfiles/images/idCard/UserCertificate/1607081013003205402.jpg | 1607081013003205402.jpg |
| bb | /userfiles/images/idCard/UserCertificate/1304011138456401591.jpg | 1304011138456401591.jpg |
| cc | /userfiles/images/idCard/UserCertificate/1304110856309061782.jpg | 1304110856309061782.jpg |
案例:身份证号加密显示
SELECT DECODE(LENGTH(IDENTIFICATION),18,REPLACE(IDENTIFICATION,SUBSTR(IDENTIFICATION, 5, 10),'**********'),
15,REPLACE(IDENTIFICATION, SUBSTR(IDENTIFICATION, 5, 7),'*******')) 身份证号,
DECODE(LENGTH(mobile_number),11,REPLACE(mobile_number,SUBSTR(mobile_number, 8, 11),'****'),mobile_number) 手机号
FROM sys_emp;
ceil() /ceiling() 向上取整
ceil(1.2) = 2floor () 向下取整
floor(1.2) = 1round() 四舍五入
11.54 开窗函数,排序取最新
【Oracle】OVER(PARTITION BY)函数用法 开窗函数 https://www.cnblogs.com/ruiser/p/5687238.html
Oracle从8.1.6开始提供分析函数
11.55 取分组取第一条记录(关键字:取最新,取第一条数据,取最后一条)
切记用 row_number 而不是 DENSE_RANK
**注:**切记 使用时不能left join 关联其他表
最优方法:
select *
from (select USERID,
JD_GPS,
WD_GPS,
dwsj,
row_number() over(partition by USERID order by dwsj desc) mm
from ydxj_dw_dwjl_2016)
where mm = 1 // 要排过序后 才能 取第一条,不能直接就用rownum = 1 这样取出的数据,和没排序的一样
方法2
select a.*
from ydxj_dw_dwjl_2016 a
where not exists (select 1
from ydxj_dw_dwjl_2016 b
where b.userid = a.userid
and b.dwsj > a.dwsj)
方法3 用于 ,mysql没有 row_number函数时
select t.*
from ydxj_dw_dwjl_2016 t
where dwsj = (
select max(t1.dwsj) from proj_base_trajectory t1 where t1.USERID = t.USERID
)
11.60 列转行
日期行转列
SELECT TO_DATE('2021-05-01', 'YYYY-MM-DD') + ROWNUM - 1 DT FROM DUAL
CONNECT BY LEVEL <= (TO_DATE('2021-05-31', 'YYYY-MM-DD') - TO_DATE('2021-05-01', 'YYYY-MM-DD') + 1)
指定字符串 分割,转行
SELECT REGEXP_SUBSTR('1,2,3', '[^,]+', 1, LEVEL) NAME
FROM dual
CONNECT BY LEVEL <= REGEXP_COUNT('1,2,3', '[^,]+')
通过 GROUP_CONCAT
SELECT GROUP_CONCAT(user_id SEPARATOR ',') AS user_ids
FROM yj_zhst_user
- 如果数据量非常大,注意
GROUP_CONCAT的默认长度限制,在 MySQL 中可以通过以下方式增大限制:
SET SESSION group_concat_max_len = 1000000;
如果
案例:
工作票接地线表每个 条记录 多个接地线直接用逗号相连,现在要获取 当前工作票 选用的所以的接地线 思路:先讲数据行转列,然后再列转行,使用in

-- 先将 指定 工作票的接地线全部查询出来,然后逗号相连
with jdx_use_temp as
(select wm_concat(t.groundwire_no) jdx_code
from PLAN_WORK_TICKET_GROUNDWIRE t
where del_flag = 0
and ticket_id = 'd439b3cd225c4667a550f172844a397a')
select *
from jdx_device t
where t.code in
(SELECT REGEXP_SUBSTR(jdx_code, '[^,]+', 1, LEVEL) NAME -- 列转行,使用in
FROM jdx_use_temp
CONNECT BY LEVEL <= REGEXP_COUNT(jdx_code, '[^,]+'))
**注:**偶尔会出现死循环,目前遇到过一次,是因为不能加where 条件,可以使用子查询
例如 FROM jdx_use_temp --> FROM (select xx from jdx_use_temp where xx=xx)
myBatis 使用collection
< foreach collection="lineIds.split(',')" item="lineId" index="index" separator=", "> 目前最优,对数据格式没有过多要求
<select id="findLineByIds" resultMap="lineVOMap">
select t.id,
t.tower_pmsid,
t.line_id,
t.tower_name,
t.tower_no,
l.line_name
from BAS_C_TOWER t,bas_c_line l
where t.line_id=l.id
<if test="lineIds != null and lineIds != ''">
AND t.LINE_ID in (
<foreach collection="lineIds.split(',')" item="lineId" index="index" separator=", ">
#{lineId}
</foreach>
)
</if>
<if test="towerIds != null and towerIds != ''">
AND t.LINE_ID in (
select distinct line_id from bas_c_tower where id in (
<foreach collection="towerIds.split(',')" item="towerId" index="index" separator=", ">
#{towerId}
</foreach>
)
)
</if>
order by t.line_id, t.tower_no
</select>
<!-- 批量更新第一种方法,通过接收传进来的参数list进行循环着组装sql -->
<update id="updateBatch" parameterType="java.util.List" >
<foreach collection="list" item="item" index="index" open="" close="" separator=";">
update standard_relation
<set >
<if test="item.standardFromUuid != null" >
standard_from_uuid = #{item.standardFromUuid,jdbcType=VARCHAR},
</if>
<if test="item.standardToUuid != null" >
standard_to_uuid = #{item.standardToUuid,jdbcType=VARCHAR},
</if>
<if test="item.gmtModified != null" >
gmt_modified = #{item.gmtModified,jdbcType=TIMESTAMP},
</if>
</set>
where id = #{item.id,jdbcType=BIGINT}
</foreach>
</update>
<!-- 批量更新第二种方法,通过 case when语句变相的进行批量更新 -->
<update id="updateBatch" parameterType="java.util.List" >
update standard_relation
<trim prefix="set" suffixOverrides=",">
<trim prefix="standard_from_uuid =case" suffix="end,">
<foreach collection="list" item="i" index="index">
<if test="i.standardFromUuid!=null">
when id=#{i.id} then #{i.standardFromUuid}
</if>
</foreach>
</trim>
<trim prefix="standard_to_uuid =case" suffix="end,">
<foreach collection="list" item="i" index="index">
<if test="i.standardToUuid!=null">
when id=#{i.id} then #{i.standardToUuid}
</if>
</foreach>
</trim>
<trim prefix="gmt_modified =case" suffix="end,">
<foreach collection="list" item="i" index="index">
<if test="i.gmtModified!=null">
when id=#{i.id} then #{i.gmtModified}
</if>
</foreach>
</trim>
</trim>
where
<foreach collection="list" separator="or" item="i" index="index" >
id=#{i.id}
</foreach>
</update>
批量更新第三种方法,用ON DUPLICATE KEY UPDATE
<insert id="updateBatch" parameterType="java.util.List">
insert into standard_relation(id,relation_type, standard_from_uuid,
standard_to_uuid, relation_score, stat,
last_process_id, is_deleted, gmt_created,
gmt_modified,relation_desc)VALUES
<foreach collection="list" item="item" index="index" separator=",">
(#{item.id,jdbcType=BIGINT},#{item.relationType,jdbcType=VARCHAR}, #{item.standardFromUuid,jdbcType=VARCHAR},
#{item.standardToUuid,jdbcType=VARCHAR}, #{item.relationScore,jdbcType=DECIMAL}, #{item.stat,jdbcType=TINYINT},
#{item.lastProcessId,jdbcType=BIGINT}, #{item.isDeleted,jdbcType=TINYINT}, #{item.gmtCreated,jdbcType=TIMESTAMP},
#{item.gmtModified,jdbcType=TIMESTAMP},#{item.relationDesc,jdbcType=VARCHAR})
</foreach>
ON DUPLICATE KEY UPDATE
id=VALUES(id),relation_type = VALUES(relation_type),standard_from_uuid = VALUES(standard_from_uuid),standard_to_uuid = VALUES(standard_to_uuid),
relation_score = VALUES(relation_score),stat = VALUES(stat),last_process_id = VALUES(last_process_id),
is_deleted = VALUES(is_deleted),gmt_created = VALUES(gmt_created),
gmt_modified = VALUES(gmt_modified),relation_desc = VALUES(relation_desc)
</insert>
通过 sum 来 实现 列传行
场景说明:地图 我的附件,查询出 当前 驿站(yz)1个、人员2个 、GT 2个 、风险 2个
查询出 4条 不同类型的 记录,这种情况前端处理数据非常不方便,需要遍历。故需要将其转为 Map 对象,数据拉平

造数据
select 'yz' as type,1 as count_num from dual-- 驿站
union all
select 'user' as type,2 as count_num from dual--人员
union all
select 'tower' as type,2 as count_num from dual-- GT
union all
select 'fx' as type,2 as count_num from dual-- 风险
目前效果
| yz_num | user_num | tower_num | fx_num |
|---|---|---|---|
| 1 | 2 | 2 | 2 |
说明: 可以用decode,但是 MySql 不能使用,只能用case when
select
sum(case when type='yz' then count_num else 0 end) as yz_num,-- 也可以用 decode
sum(case when type='user' then count_num else 0 end) as user_num,
sum(case when type='tower' then count_num else 0 end) as tower_num,
sum(case when type='fx' then count_num else 0 end) as fx_num
from (
select 'yz' as type,1 as count_num from dual-- 驿站
union all
select 'user' as type,2 as count_num from dual--人员
union all
select 'tower' as type,2 as count_num from dual-- GT
union all
select 'fx' as type,2 as count_num from dual-- 风险
)aa
案例: 对人员岗位归类,positionName多个岗位逗号拼接的,如果存在 总监理工程师--> 总结,否则 总监代表--> 总代 ,否则 监理员 --> 监理员 ,都不是 则返回其他
select b.emp_id,
case
when INSTR(b.positionName, '总监理工程师') > 0 then '总监' --总监
when INSTR(b.positionName, '总监代表') > 0 then '总代' --总代
when INSTR(b.positionName, '监理员') > 0 then '监理员' --监理员
ELSE '其他' END as position
from v_user_position b
where b.positionName is not null
11.61 行转列
wm_concat 实现行转列(存在限定,拼接超过4000后异常)
mysql 等价的是
GROUP_CONCAT函数
select t.office_id,
wm_concat(t.area_id) areaIds, --replace(wm_concat(area_id),',','|') 通过 replace替换成需要的连接字符串
wm_concat(to_char(a.name)) as areaNames-- 对于中文可能会出现 转义
from ZHCG_OFFICE_MANAGE_AREA t, sys_area a
where t.del_flag = '0'
and a.del_flag = '0'
and t.area_id = a.id
group by office_id
- xmlagg
wm_concat ---函数实现字段合并 将返回的多条数据,,合并到一起,行转列,但是存在一个问题,拼接超过4000后异常
1.select XMLAGG(XMLELEMENT(E, name || ',')).EXTRACT('//text()').getclobval() as names from sys_user 但是好像不能使用分组函数
- xmlagg(xmlparse(content 拼接字段 || ','wellformed) order by 排序字段).getclobval()
案例:
SELECT
rtrim(xmlagg(xmlparse(content u.emp_name || ',' wellformed) ) .getclobval(), ',') userNames,
rtrim(xmlagg(xmlparse(content p.emp_id || ',' wellformed) ) .getclobval(), ',') userIds,
p.RULE_ID
from PROJ_BASE_ATTENDANCE_PERSON p
left join sys_emp u on u.id=p.emp_id
group by p.RULE_ID
注: rtrim(字段, ',') 去掉右边最后一个逗号
通过xmlagg讲数据转为clob ,也会存在字符缓存去限定长度
dbms_lob.substr( substr(rtrim(xmlagg(xmlparse(content a.id || ',' wellformed)) .getclobval(),',') ,0,200))
listagg 函数
SELECT listagg(t.ename,',') WITHIN GROUP(ORDER BY t.sal) FROM scott.emp t group by xxx;
- 使用REGEXP_SUBSTR
--1.
SELECT REGEXP_SUBSTR ('1,2,3', '[^,]+', 1,rownum)
from dual connect by rownum<=LENGTH ('1,2,3') - LENGTH (regexp_replace('1,2,3', ',', ''))+1;
-- 2.
select REGEXP_SUBSTR(t.rolecode, '[^,]+', 1, l) type
from (select '1,2' rolecode from dual) t,
(SELECT LEVEL l FROM DUAL CONNECT BY LEVEL <= 100) b
WHERE l <= LENGTH(t.rolecode) - LENGTH(REPLACE(rolecode, ',')) + 1
案例场景: 前端传递一个逗号拼接的字符串,sql中需要用in
select pe.emp_id from SYS_EMP_POST_EMP pe
where pe.position_id in (
SELECT REGEXP_SUBSTR (${positionIds}, '[^,]+', 1,rownum)
from dual connect by rownum <![CDATA[ <= ]]> LENGTH (${positionIds}) - LENGTH (regexp_replace(${positionIds}, ',', ''))+1
)
--'26438E087E604071886C69BC39B8A176,4358B8B6E93F4119847FF73766B72733'
11.65 ORACLE WITH AS 用法
with as优点 (相当于 创建一个临时表,然后后面可以直接调用 ) 增加了sql的易读性,如果构造了多个子查询,结构会更清晰; 更重要的是:“一次分析,多次使用”,这也是为什么会提供性能的地方,达到了“少读”的目标;
with e as (select * from scott.emp e where e.empno=7499)-- 相当于创建一个临时表
select * from e;
with
e as (select * from scott.emp),
d as (select * from scott.dept)
select * from e, d where e.deptno = d.deptno;
11.70 resultMap
resultMap可以实现将查询结果映射为复杂类型的pojo,比如在查询结果映射对象中包括pojo和list实现一对一查询和一对多查询
<resultMap type="cn.semdo.modules.projjl.entity.ProjJlEngineer" id="projJlEngineerMap">
<id column="ID" property="id"/>
<id column="engineerName" property="engineerName"/>
<collection property="projJlPositionList" ofType="cn.semdo.modules.projjl.entity.ProjJlPosition" column="engineerId">
<id column="positionId" property="id"/>
<id column="engineerId" property="engineerId"/>
<id column="positionName" property="name"/>
</collection>
</resultMap>
<select id="projJlEngineerList" resultMap="projJlEngineerMap">
SELECT
a.id,
a.engineer_Name as engineerName,
p.id AS "positionId",
p.engineer_id AS "engineerId",
p.name AS "positionName"
FROM proj_jl_engineer a
left join PROJ_JL_POSITION p on p.engineer_id = a.id
</select>
<!--column不做限制,可以为任意表的字段,而property须为type 定义的pojo属性-->
<resultMap id="唯一的标识" type="映射的pojo对象">
<id column="表的主键字段,或者可以为查询语句中的别名字段" jdbcType="字段类型" property="映射pojo对象的主键属性" />
<result column="表的一个字段(可以为任意表的一个字段)" jdbcType="字段类型" property="映射到pojo对象的一个属性(须为type定义的pojo对象中的一个属性)"/>
<association property="pojo的一个对象属性" javaType="pojo关联的pojo对象">
<id column="关联pojo对象对应表的主键字段" jdbcType="字段类型" property="关联pojo对象的主席属性"/>
<result column="任意表的字段" jdbcType="字段类型" property="关联pojo对象的属性"/>
</association>
<!-- 集合中的property须为oftype定义的pojo对象的属性-->
<collection property="pojo的集合属性" ofType="集合中的pojo对象">
<id column="集合中pojo对象对应的表的主键字段" jdbcType="字段类型" property="集合中pojo对象的主键属性" />
<result column="可以为任意表的字段" jdbcType="字段类型" property="集合中的pojo对象的属性" />
</collection>
</resultMap>
使用:Map<String, Object> getYhBihuanStatisData(JSONObject params);
<resultMap type="java.util.Map" id="yhBihuanStatisDataResult">
<result property="yhs" column="yhs" javaType="java.lang.Long" />
<result property="ybh" column="ybh" javaType="java.lang.Long" />
</resultMap>
<select id="getYhBihuanStatisData" resultMap="yhBihuanStatisDataResult" parameterType="com.alibaba.fastjson.JSONObject">
SELECT
count(1) yhs,
sum(case status when '5' then 1 else 0 end) ybh,
sum(case when FIND_TIME like '2022-09%' then 1 else 0 end) byxz,
sum(case when FIND_TIME like '2022-09%' and status = '5' then 1 else 0 end) bybh
FROM yh_op_record
WHERE del_flag = '0'
<!-- status:隐患状态
1:隐患库(暂存) 2:上报审核中 3:隐患管控中 4:闭环审核中
5:已闭环(正常) 6:重复上报(DEL_FLAG设为1) 7:误报(DEL_FLAG设为1)
-->
AND status != '1'
<if test="opTeamId!=null and opTeamId != ''">
AND op_team_id = #{opTeamId}
</if>
<if test="opOrgId!=null and opOrgId != ''">
AND op_org_id = #{opOrgId}
</if>
</select>
通过java 构造
// 以 parentId 分组(使用并行流)
Map<Long, List<TreeNode>> parentMap = nodeList.parallelStream()
.collect(Collectors.groupingByConcurrent(TreeNode::getParentId));
// 根节点列表
List<TreeNode> rootList = parentMap.get(0L);
// 递归构造树形结构
if (rootList != null) {
rootList.parallelStream().forEach(root -> {
buildTree(root, parentMap);
});
}
/**
* 递归构造树形结构
*
* @param node 节点
* @param parentMap 根据 parentId 分组的 Map
*/
private static void buildTree(TreeNode node, Map<Long, List<TreeNode>> parentMap) {
List<TreeNode> childList = parentMap.get(node.getId());
node.setChildren(childList);
if (childList != null) {
childList.forEach(child -> {
buildTree(child, parentMap);
});
}
}
工具类
通过java 构造树结构
List<TreeBean> tree = JavaFormatTreeUtil.getTree(list, "id",officeId);
js 构造
/**
* 组装树结构
* 考虑该功能可能需要离线使用,所以将数据获取到,通过js递归的形式,来组装数据
*/
var getTree=function(treeData,parentId){
var treeArr=[];
for(var i=0;i<treeData.length;i++){
var node=treeData[i];
if(node.parentId==parentId ){
var newNode={
id:node.id,
name:node.name,
parentId:node.parentId,
type:node.type,
nodeType:node.nodeType,
children:getTree(treeData,node.id)
};
treeArr.push(newNode);
}
}
return treeArr;
}
var treeArr=getTree(data,0);//将后台返回的数据,组装成树结构
resultMap 构造树结构
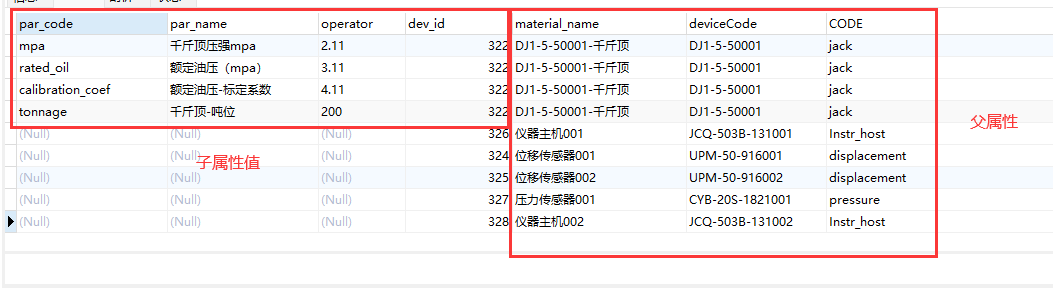
<resultMap id="selectMaterialMap" type="cn.semdo.gdzjz.detectionManage.domain.vo.MaterialVO">
<result column="dev_id" property="id"/>
<result column="material_name" property="materialName"/>
<result column="deviceCode" property="deviceCode"/>
<result column="code" property="code"/>
<collection property="expandVOList" resultMap="expandResult" javaType="java.util.List"/>
</resultMap>
<resultMap id="expandResult" type="cn.semdo.gdzjz.detectionManage.domain.vo.MaterialExpandVO">
<result property="operator" column="operator"/>
<result property="parCode" column="par_code"/>
<result property="parName" column="par_name"/>
</resultMap>
<select id="selectMaterialData" resultMap="selectMaterialMap">
select e.par_code,e.par_name,e.operator,d.dev_id,info.material_name,t.code,info.material_Code as deviceCode
from zjjc_detection_device_relation d
inner join material_info info on info.id=d.dev_id
left join material_type t on t.id=info.typeid
left join material_info_expand e on e.material_id=d.dev_id
where d.del_flag=0 and d.proj_id=#{proId}
</select>
11.80 特殊字符
- 大于、小于
<![CDATA[ <= ]]>
11.81 oracle 查询记录为空,返回默认值 --- 在创建任务单单号的时候的应用
场景: 查询时 如果查询到那么就用查询的结果,如果查询不到,那么就给定一个默认值
分2中情况
1.可能不存在返回值 ,即一条数据都没有:
案例 表 dsj_line_tower_relation 存放 线路表存在的线路和 GT表中实际的线路
select nvl(MAX(t.tower_line_id),'bf3c8dd107a04d918a1d7f59365ccc26') from dsj_line_tower_relation t where line_id='bf3c8dd107a04d918a1d7f59365ccc26' --(使用max一定会有返回值,这样搭配 nvl 就可以实现返回值一定有结果)
传递我们指定的线路id,如果在****dsj_line_tower_relation**** 表中存在记录,那么就用查询的tower_line_id 否则,我们就返回我们传递的参数

查询时没有任何返回值,那么时不能用nvl() 来实现上面的效果
- 一定存在返回值,但是可能存在为空
select nvl(t.line_id,0) from ..................

11.90 存储过程
场景:每天根据 V_USER_WEIPAI 表(存放设备主人,GT,设备id,应该巡视次数)
https://blog.csdn.net/dwenxue/article/details/82257944 创建存储过程(带参数)
create or replace procedure PROC_WEIPAI_OP_EVERY_DAY as
--以机代巡中 设备巡视 每天统计
v_op_num NUMBER(10); -- 每天对应的 设备应拍次数(设置变量,下文中 会用到上面的查询结果)
begin
select nvl(max(OP_NUM), 3) into v_op_num from YDXJ_JOB_OP_NUM where trunc(OP_TIME) = trunc(SYSDATE); -- 每天对应的 设备应拍次数 赋值 (nvl(max(OP_NUM),0) 保证一定有值)
DELETE FROM YDXJ_WEIPAI_OP_COUNT_DAY WHERE trunc(OP_TIME) = trunc(SYSDATE); -- 删除今天数据,防止 数据重复添加
insert into ydxj_weipai_op_count_day (user_id, weipai_id, tower_id, op_time, should_op_num, op_num)
select a.userid, a.WEIPAIRECORD_ID, a.tower_id, sysdate,
v_op_num, -- 每个设备 应该巡视次数 (是上面语句中查询出来的数值)
nvl(op_.op_num,0) --每个设备 实际巡视次数
from V_USER_WEIPAI a
left join (select count(op.opid) as op_num, WEIPAIRECORD_ID,op.OPUSERID---讲数据分组后 left join 会提高查询速度
from ydxj_job_op op
where trunc(OPTIME) = trunc(SYSDATE)
and op.WEIPAIRECORD_ID is not null
group by WEIPAIRECORD_ID,op.OPUSERID) op_
on a.WEIPAIRECORD_ID = op_.WEIPAIRECORD_ID and op_.OPUSERID=a.userid;
Commit;
exception
when others then
raise;
rollback;
end;
创建 能传递参数的 存储过程
create or replace procedure test_page(
page_start in int,page_end in int,page_count out int,
page_emps out sys_refcursor)
as
begin
select count(*) into page_count from employees;
open page_emps for
select * from
(select rownum rn,e.* from employees e
where rownum <= page_end)
where rn >= page_start;
end test_page;
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.lxj.mapper.EmployeeMapper">
<select id="getEmpById" resultType="com.lxj.bean.Employee">
select EMPLOYEE_ID id,LAST_NAME lastName,EMAIL email from employees
where EMPLOYEE_ID = #{id}
</select>
<!-- public void getEmpsByPage();
statementType="CALLABLE":调用存储过程,默认是PREPARED
call 不能丢,否则识别不出
-->
<select id="getEmpsByPage" statementType="CALLABLE">
{call test_page(
#{start,mode=IN,jdbcType=INTEGER},
#{end,mode=IN,jdbcType=INTEGER},
#{count,mode=OUT,jdbcType=INTEGER},
#{emps,mode=OUT,jdbcType=CURSOR,javaType=ResultSet,resultMap=TestPge}
)}
</select>
<resultMap type="com.lxj.bean.Employee" id="TestPge">
<id column="EMPLOYEE_ID" property="id"/>
<result column="LAST_NAME" property="lastName"/>
<result column="EMAIL" property="email"/>
</resultMap>
</mapper>
11.91 数据库定时器

19.100 DBLINK
需要保证 两个数据库之间网络是相通的,而不是 执行plsql 的本地的电脑和 目标数据库之间想通
查询数据库中的dblink select * from dba_db_links;
删除 drop database LINK SDTXJB_DBLINK;
--使用:比如协同办公需要移动巡检中的线路表(bas_c_linedsa) sdt_tyxxpt.bas_c_line@SDT_TYXXPT_DBLINK
create database link SDT_TYXXPT_DBLINK
connect to sdt_tyxxpt identified by sdt_tyxxpt
using '(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.10.225)(PORT = 1521))
)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SID = yjdb2)
)
)';
create database link SDT_TYXXPT_DBLINK
connect to sdt_tyxxpt identified by sdt_tyxxpt
using '218.23.109.123:9522/yjdb';
19.110 oracle 自定义函数
参考https://blog.csdn.net/jumtre/article/details/38092067
--第一种不带参数:
create or replace function get_user
return varchar2 is Result varchar2(50); --定义变量(返回值)
begin
select username into Result from user_users; --into 赋值,不要忘了加分号结尾
return(Result); --返回值
end get_user;
--第二种带参:
create or replace function get_sal(empname in varchar2)
return numbe is Result number;
begin
select sal into Result from emp where ename=empname;
return(Result);
end;
自定义函数验证是否为数字
https://blog.csdn.net/vincentlee_/article/details/15336557
CREATE OR REPLACE FUNCTION isnumeric(str IN VARCHAR2)
RETURN NUMBER
IS
v_str FLOAT;
BEGIN
IF str IS NULL
THEN
RETURN 0;
ELSE
BEGIN
SELECT TO_NUMBER (str)
INTO v_str
FROM DUAL;
EXCEPTION --异常
WHEN INVALID_NUMBER
THEN
RETURN 0;
END;
RETURN 1;
END IF;
END isnumeric;
经纬度距离计算
CREATE OR REPLACE FUNCTION F_DISTANCE (cx in number,cy in number,sx in number, sy in number)
RETURN NUMBER
is
d number;
x number;
y number;
r number;
pi number;
begin
r:=6371229;--地球半径
pi:=3.14159265358979323;--圆周率
x:=(sx-cx)*pi*r*cos((sy+cy)/2*pi/180)/180;
y:=(sy-cy)*pi*r/180;
d:=SQRT(power(x,2)+power(y,2));
D:=ROUND(D,2);
RETURN d;
end ;
11.120 查询指定用户 表名+数据量+表备注
SELECT t.table_name, t.num_rows, f.comments
FROM all_tables t
INNER JOIN ( SELECT * FROM all_tab_comments WHERE OWNER = 'CPMS_DEV' ) f ON t.table_name = f.table_name
WHERE t.OWNER = 'CPMS_DEV'
11.130 时间排序,存在null 导致 排列到最前面
Nulls first (记录将排在最前)和nulls last(记录将排在最后)是Oracle Order by支持的语法
select * from FORUM t order by last_reply_time desc nulls last ,id desc ;
select *
from (select row_number() over(partition by id order by receive_time desc nulls last) mm,a.*
from sys_push_send_ref_temp a
) where mm = 1
decode
decode(filed,null,’张三’, filed)表示当filed为空时则返回’张三’,如果不为空则返回filed本来的值(不仅可以判断null,也可以判断特定的值)
使用 nvl
select * from FORUM t order by NVL(last_reply_time, to_date('1970-01-01 00:00:00','yyyy/MM/dd/hh24/mi/ss')) desc ;
11.140 案例:
消息 有多层级,现在需要 获取 根节点并展示指定用户最新的消息
with sys_push_send_ref_temp as(
select root_modules_id as id,root_modules_name as modulesName,root_modules_code,aa.modules_id,aa.name,root_msg_url_app as msgUrlApp,
aa.root_modules_icon modulesIcon,bb.receive_status,bb.receive_time,bb.message,bb.CONTENT_ID
from (select connect_by_root id as root_modules_id,--
connect_by_root MODULES_NAME as root_modules_name,
connect_by_root MODULES_CODE as root_modules_code,
connect_by_root modules_icon as root_modules_icon,
connect_by_root msg_url_app as root_msg_url_app,
id modules_id, t.MODULES_NAME,MODULES_CODE,
lpad(' - - - - - - -', (level - 1) * 10, ' ') || t.MODULES_NAME as name --节点名称(带缩进)
from sys_Push_Modules t where del_flag = '0'
-- 核心写法,通过递归 重构 sys_Push_Modules 获取每个消息类型的根节点信息
start with PARENT_ID is null --递归的写法,从指定节点,查询其下面的所有数据
connect by t.PARENT_ID = prior t.id) aa
left join (select a.receive_status,a.receive_time,c.modules_id,c.message,a.CONTENT_ID-- 用来获取 每个类型的消息
from sys_push_send_ref a, sys_push_content c
where c.id = a.content_id and a.receive = '02049cdfa3904602add9b85e2951f767') bb
on bb.modules_id = aa.modules_id
)
select a.id,a.modulesIcon,b.count,a.modulesName,a.receive_time,a.message,a.msgUrlApp
from (
select id,modulesIcon,modulesName,message,msgUrlApp ,receive_time
from (select row_number() over(partition by id order by receive_time desc nulls last) mm,a.*
from sys_push_send_ref_temp a
) where mm = 1 -- 获取每个 更节点 最新的一条消息
)a
left join(-- 获取未读消息的数量
select count(1) count,id
from sys_push_send_ref_temp a
where receive_status=0 and CONTENT_ID is not null
group by id
) b on b.id=a.id
order by a.receive_time desc nulls last
主要思路: 用递归遍历,connect_by_root 标记出 每个消息类型对应的 根节点 信息,这样关联消息表,就能获取每个消息对应的根节点id。然后取最新一条

11.200
between xx and yy ;
11.210 oracle 对时间的处理
1. trunc
select trunc(sysdate,'HH24')-1/24 from dual; -- 当前时间前一个小时 并且小时取整 2021/4/30 13:00:00
select TRUNC(SYSDATE, 'MM') from dual;-- 2023/8/1
-- TRUNC(SYSDATE, 'YYYY') 将当前日期截断为当前年份的第一天,然后通过加上 INTERVAL '1' YEAR - INTERVAL '1' DAY 得到当前年份的最后一天
SELECT TRUNC(SYSDATE, 'YYYY') + INTERVAL '1' YEAR - INTERVAL '1' DAY AS year_end FROM dual; -- 2023/12/31
SELECT TRUNC(ADD_MONTHS(SYSDATE, 12), 'YYYY') AS next_year_first_day FROM dual; -- 下一年的最后一天
2.日期行转列
SELECT TO_DATE('2021-05-01', 'YYYY-MM-DD') + ROWNUM - 1 DT FROM DUAL
CONNECT BY LEVEL <= (TO_DATE('2021-05-31', 'YYYY-MM-DD') - TO_DATE('2021-05-01', 'YYYY-MM-DD') + 1)
3. 两时间相加减
https://www.cnblogs.com/zhaojinhui/p/3999469.html
注: Oracle date 日期相减 注意 sysdate 为date 类型,所有如果 TIMESTAMP(6) 类型责需要
sysdate-to_date(to_char(time,'yyyy-mm-dd hh24-mi-ss'),'yyyy-mm-dd hh24-mi-ss')
--oracle 两个时间相减默认的是天数
--oracle 两个时间相减默认的是天数*24 为相差的小时数
--oracle 两个时间相减默认的是天数*24*60 为相差的分钟数
--oracle 两个时间相减默认的是天数*24*60*60 为相差的秒数
--MONTHS_BETWEEN(date2,date1)
--给出date2-date1的月份
select months_between('19-12月-1999','19-3月-1999') mon_between from dual;
--MON_BETWEEN
select months_between(to_date('2000.05.20','yyyy.mm.dd'),to_date('2005.05.20','yyyy.dd')) mon_betw from dual;
-- MON_BETW
-- Oracle计算时间差表达式
--获取两时间的相差豪秒数
select ceil((To_date('2008-05-02 00:00:00' , 'yyyy-mm-dd hh24-mi-ss') - To_date('2008-04-30 23:59:59' , 'yyyy-mm-dd hh24-mi-ss')) * 24 * 60 * 60 * 1000) 相差豪秒数 FROM DUAL;
--获取两时间的相差秒数
select ceil((To_date('2008-05-02 00:00:00' , 'yyyy-mm-dd hh24-mi-ss') - To_date('2008-04-30 23:59:59' , 'yyyy-mm-dd hh24-mi-ss')) * 24 * 60 * 60) 相差秒数 FROM DUAL;
--获取两时间的相差分钟数
select ceil(((To_date('2008-05-02 00:00:00' , 'yyyy-mm-dd hh24-mi-ss') - To_date('2008-04-30 23:59:59' , 'yyyy-mm-dd hh24-mi-ss'))) * 24 * 60) 相差分钟数 FROM DUAL;
--获取两时间的相差小时数
select ceil((To_date('2008-05-02 00:00:00' , 'yyyy-mm-dd hh24-mi-ss') - To_date('2008-04-30 23:59:59' , 'yyyy-mm-dd hh24-mi-ss')) * 24) 相差小时数 FROM DUAL;
--获取两时间的相差天数
select ceil((To_date('2008-05-02 00:00:00' , 'yyyy-mm-dd hh24-mi-ss') - To_date('2008-04-30 23:59:59' , 'yyyy-mm-dd hh24-mi-ss'))) 相差天数 FROM DUAL;
----------------------------------------
注:天数可以2个日期直接减,这样更加方便
----------------------------------------
--获取两时间月份差
select (EXTRACT(year FROM to_date('2009-05-01','yyyy-mm-dd')) - EXTRACT(year FROM to_date('2008-04-30','yyyy-mm-dd'))) * 12 +
EXTRACT(month FROM to_date('2008-05-01','yyyy-mm-dd')) - EXTRACT(month FROM to_date('2008-04-30','yyyy-mm-dd')) months
from dual;
--------------------------------------
注:可以使用months_between函数,更加方便
--------------------------------------
--获取两时间年份差
select EXTRACT(year FROM to_date('2009-05-01','yyyy-mm-dd')) - EXTRACT(year FROM to_date('2008-04-30','yyyy-mm-dd')) years from dual;
select sysdate,add_months(sysdate,12) from dual; --加1年
select sysdate,add_months(sysdate,1) from dual; --加1月
select sysdate,TO_CHAR(sysdate+7,'yyyy-mm-dd HH24:MI:SS') from dual; --加1星期
select sysdate,TO_CHAR(sysdate+1,'yyyy-mm-dd HH24:MI:SS') from dual; --加1天
select sysdate,TO_CHAR(sysdate+1/24,'yyyy-mm-dd HH24:MI:SS') from dual; --加1小时
select sysdate,TO_CHAR(sysdate+1/24/60,'yyyy-mm-dd HH23:MI:SS') from dual; --加1分钟
select sysdate,TO_CHAR(sysdate+1/24/60/60,'yyyy-mm-dd HH23:MI:SS') from dual; --加1秒
select sysdate+7 from dual; --加7天
4.oracle验证2个时间是否有交集,时间重叠
select *
from test_table
where (startTime > a AND startTime < b) OR
(startTime < a AND endTime > b) OR
(endTime > a AND endTime < b)
5. 年份比较
SELECT *
FROM your_table
WHERE EXTRACT(YEAR FROM your_date) = EXTRACT(YEAR FROM SYSDATE); -- 验证your_date 是否是 今年
11.220 oracle 递归

select
connect_by_root t.name as func_name_4_root ,t.type
,lpad(' - - - - - - -', (level - 1) * 10, ' ') || t.name as "name" --节点名称(带缩进)
, SYS_CONNECT_BY_PATH(name, '/') as pName
from sys_office t
start with id='xjbwgzb' --递归的写法,从指定节点,查询其下面的所有数据 (不可为空,否则查出的数据,会重复)
connect by t.parent_id=prior t.id;
说明:
CONNECT_BY_ROOT 返回当前节点的最顶端节点 ---->connect_by_root t.name 返回的就是根节点的名称
CONNECT_BY_ISLEAF 判断是否为叶子节点,如果这个节点下面有子节点,则不为叶子节点
LEVEL 伪列表示节点深度 ------> 可以作为节点的层级
SYS_CONNECT_BY_PATH函数显示详细路径,并用“/”分隔----> 拼接节点,可以找到所以父节点
参考:https://blog.csdn.net/feier7501/article/details/21815691
向上递归 id 最小级别
select distinct name,type,id
from sys_office t
start with id = '0192e1d8c9d34eab89ec0csedwewefweffw3434345633s'
connect by prior parent_id = id
向下递归 id 最大级别
select distinct name ,type,id
from sys_office t
start with t.id = 'xjbwgzb'
connect by prior id = parent_id
案例:场景:查询人员的所属部门,office表结构为 公司-部门-团队,其中部门和团队都挂人员,而团队下的人员也要归属于部门下
select * from sys_office t
where t.type = '2' --type=2 表示团队
connect by prior t.id=t.parent_id
start with t.id ='xxxxxx' ---当前人员的所属机构
11.230 grant 权限 on 数据库对象 to 用户
# 给 SDT_XJB系统 添加 SDT_IMOA 用户下的SYS_USER 表的select权限
grant select on SYS_USER to SDT_IMOA ;
#
select 'grant select on '||table_name ||' to SDT_XJB ;' from all_tables where owner='SDT_IMOA';
说明: 现在需要创建一个视图,用来 协同办公和巡检保 用户表对照
分别 在 SDT_XJB用户下执行 grant select on SYS_USER to SDT_IMOA ;
在 SDT_IMOA用户下执行 grant select on SYS_USER to SDT_XJB;
create or replace view v_user_xjb_imoa as(
/*
巡检保和 协同办公人员对照表
*/
select imoa_u.login_name as imoa_login_name,
imoa_u.id as imoa_id,
imoa_u.name as imoa_name,
imoa_u.office_id as imoa_office_id,
xjb_u.login_name as xjb_login_name,
xjb_u.id as xjb_id,
xjb_u.name as xjb_name,
xjb_u.office_id as xjb_office_id
from SDT_IMOA.sys_user imoa_u, SDT_XJB.sys_user xjb_u
where imoa_u.login_name = xjb_u.login_name -- imoa_u.del_flag=0 and xjb_u.del_flag=0
);
11.240 聚合
数据库中找到表中重复数据 oracle查询重复数据方法
找到表中 model_name 出现重复的记录
select * from BAS_TOWER_TYPE where MODEL_NAME in (
select MODEL_NAME from BAS_TOWER_TYPE where model_name='J27102'
group by MODEL_NAME
having count(id) > 1
)
11.250 查询数据库中表是否被锁
select object_name,machine,s.sid,s.serial#
from v$locked_object l,dba_objects o ,v$session s
where l.object_id = o.object_id and l.session_id=s.sid;
11.500 数据库异常
1.数据库 连接不上,也不报错
可能是 listener.log 文件已经达到4G 无法再继续写入参考:https://blog.csdn.net/obgnahs/article/details/81410569
解决:删除D:\app\Administrator\diag\tnslsnr\计算机名\listener\trace目录下listener.log文件
重启service服务及数据库实例服务
2. 数据库锁表
查看Oracle被锁的表以及如何解锁:https://blog.csdn.net/liusa825983081/article/details/80448945
- 1.查看是否有被锁的表:
select b.owner,b.object_name,a.session_id,a.locked_mode
from v$locked_object a,dba_objects b
where b.object_id = a.object_id
- 2.查看是哪个进程锁的
select b.username,b.sid,b.serial#,logon_time
from v$locked_object a,v$session b
where a.session_id = b.sid order by b.logon_time
| username | sid | serial# | logon_time |
|---|---|---|---|
| SDT_XJB | 435 | 29253 | 2021/10/8 9:04:22 |
杀死进程
alter system kill session 'sid,serial#';
-- alter system kill session '435,29253';
Oracle ORA-12514 解决办法
- 找到listener.ora监听文件,具体位置如:
C:\app\Administrator\product\11.2.0\dbhome_1\network\admin\listener.ora
2.在lisener.ora文件中添加下方加红加粗部分:
# listener.ora Network Configuration File: C:\app\Administrator\product\11.2.0\dbhome_1\network\admin\listener.ora
# Generated by Oracle configuration tools.
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = CLRExtProc)
(ORACLE_HOME = C:\app\Administrator\product\11.2.0\dbhome_1)
(PROGRAM = extproc)
(ENVS = "EXTPROC_DLLS=ONLY:C:\app\Administrator\product\11.2.0\dbhome_1\bin\oraclr11.dll")
)
# ==============添加下面的语句===========
(SID_DESC =
(GLOBAL_DBNAME = ORCL)
(ORACLE_HOME = C:\app\Administrator\product\11.2.0\dbhome_1)
(SID_NAME = ORCL)
)
# =================================
)
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = WIN-UBKOOK0BP2K.geostar.com.cn)(PORT = 1521))
)
)
ADR_BASE_LISTENER = C:\app\Administrator
ORA-01033 问题解决办法
https://www.cnblogs.com/iqingchun/p/13538103.html
Oracle归档日志满了导致无法启动ora-03113
案例:(使用过)
# 1.登陆(https://www.cnblogs.com/gmq-sh/p/5980127.html)
sqlplus /nolog
SQL> connect /as sysdba
# 2.检查flash recovery area的使用情况,可以看见archivelog已经很大了,达到99.94
SQL> select * from V$FLASH_RECOVERY_AREA_USAGE;

# 3.计算flash recovery area已经占用的空间
SQL> select sum(percent_space_used)*3/100 from v$flash_recovery_area_usage;

# 4.修改FLASH_RECOVERY_AREA的空间修改为8GB,修改前确认磁盘有足够空间
SQL> ALTER SYSTEM SET DB_RECOVERY_FILE_DEST_SIZE=8g
# 5.清理一下archivelog归档日志,生产环境建议备份
## 5.1查询日志目录位置
show parameter recover;
## 5.2删除归档日志,orcl是数据库实例名 (手动删除文件)
D:\app\Administrator\flash_recovery_area\orcl\ARCHIVELOG
# 6.使用rman 操作
$ rman
RMAN> connect target sys/sys_passwd
crosscheck backup;
delete obsolete;
delete expired backup;
crosscheck archivelog all;
delete expired archivelog all;
#### 此步会有提示,输入 YES 回车
host; //退出rman
# 7.确认是否操作成功
sqlplus /nolog
SQL> connect /as sysdba
SQL> select * from V$FLASH_RECOVERY_AREA_USAGE;
ORACLE 归档日志打开关闭方法
sql> archive log list; #查看是否是归档方式
sql> alter system set log_archive_start=false scope=spfile; #禁用自动归档
sql> shutdown immediate;
sql> startup mount; #打开控制文件,不打开数据文件
sql> alter database noarchivelog; #将数据库切换为非归档模式
sql> alter database open; #将数据文件打开
sql> archive log list; #查看此时便处于非归档模式
//=== 待测试
sqlplus / as sysdba
shutdown abort ----关闭进程
startup mount ---- 装载数据库
select * from v$recovery_file_dest; ---查询归档日志
ALTER SYSTEM SET DB_RECOVERY_FILE_DEST_SIZE=10737418240; --设置归档日志空间为10G
https://www.cnblogs.com/-txf-/p/11572942.html
oracle归档日志满了无法启动数据库问题解决记录
sqlplus /nolog
conn /as sysdba
上面的登录方式提示12560协议适配器错误
sqlplus sys/sys@orcl as sysdba 这个语句就可以直接登录
conn sys/sys as sysdba;
然后将oracle关闭shutdown immediate;
再启动到mount模式 statrup mount
更改数据库的归档模式
SELECT * FROM V$FLASH_RECOVERY_AREA_USAGE;--查询归档日志大小
select log_mode from v$database;--查询归档模式
alter database noarchivelog;--更改数据库到非归档模式
接下来删除过多的归档日志文件
先物理删除日期较前的归档日志(可以剪切到别处),归档日志文件位置D:\app\Administrator\flash_recovery_area\orcl\ARCHIVELOG
再打开一个cmd窗口
执行 $ rman target / nocatalog;
crosscheck archivelog all;--检查归档日志文件
delete expired archivelog all;--删除过期的日志文件
接下来重新启动oracle即可
rman 执行 可能会报错,前面加上$
include 的用法
<sql id="sqlid">
res_type_id,res_type
</sql>
<select id="queryPubResType" parameterType="com.property.vo.PubResTypeVO" resultMap="PubResTypeList">
select a.res_type_id,
<include refid="sqlid">
<property name="AI_RES_TYPE_ID" value="a.res_type_id"/>
<property name="lng" value="#{lngId}"/>
<property name="female" value="'女'"/>
</include> as res_type
from pub_res_type a
</select>
<select id="queryPubResType" parameterType="com.property.vo.PubResTypeVO" resultMap="PubResTypeList">
select a.res_type_id,
<include refid="sqlid"/>
from pub_res_type a
</select>
验证是否包含(是否有交集)

-- 场景1
(#{选择结束点} BETWEEN 开始点 and 结束点)
-- 场景2、3
or (#{选择开始点} BETWEEN 开始点 and 结束点)
-- 场景4
or (
#{选择结束点} >= 结束点 and #{选择开始点} <![CDATA[ <= ]]> 开始点
)
表空间相关
查询表空间大小
SELECT
a.tablespace_name, -- 表空间名称
b.bytes / 1024 / 1024 AS total_size_mb, -- 总大小 (MB)
(b.bytes - NVL(c.bytes, 0)) / 1024 / 1024 AS used_size_mb, -- 已使用 (MB)
NVL(c.bytes, 0) / 1024 / 1024 AS free_size_mb -- 可用 (MB)
FROM
dba_tablespaces a
JOIN
(SELECT tablespace_name, SUM(bytes) AS bytes
FROM dba_data_files
GROUP BY tablespace_name) b ON a.tablespace_name = b.tablespace_name
LEFT JOIN
(SELECT tablespace_name, SUM(bytes) AS bytes
FROM dba_free_space
GROUP BY tablespace_name) c ON a.tablespace_name = c.tablespace_name
ORDER BY
a.tablespace_name;
表空间满了
-- 查询表空间对应的文件位置
select name from v$datafile;
-- 查询总量 size_mb
SELECT file_name,
bytes/1024/1024 AS size_mb,
(bytes - NVL(free_bytes, 0))/1024/1024 AS used_mb
FROM (
SELECT df.file_name,
df.bytes,
SUM(fs.bytes) AS free_bytes
FROM dba_data_files df
LEFT JOIN dba_free_space fs ON df.file_id = fs.file_id
WHERE df.file_name = 'D:\APP\LISHIHUAN\ORADATA\ORCL\SDT_IMOA.DBF'
GROUP BY df.file_name, df.bytes
);
-- 2560M 这个数值要比上面查询到的size_mb 大
ALTER DATABASE DATAFILE 'D:\APP\LISHIHUAN\ORADATA\ORCL\SDT_IMOA.DBF' RESIZE 2560M;
查询表空间中表、索引占用空间
SELECT
a.tablespace_name,
b.segment_name,
b.segment_type,
SUM(b.bytes) / 1024 / 1024 AS used_size_mb
FROM
dba_segments b
JOIN
dba_tablespaces a ON b.tablespace_name = a.tablespace_name
WHERE a.tablespace_name = 'SDT_IMOA' -- 替换为你的表空间名称
GROUP BY
a.tablespace_name, b.segment_name, b.segment_type
ORDER BY
used_size_mb DESC;
创建只读用户
- 原始用户 SDT_YJWZ
- 创建只读用户semdo_wz
-- 1. 创建用户
CREATE USER semdo_wz IDENTIFIED BY semdo_wz;
-- 2. 授予该用户连接到数据库的权限
GRANT CONNECT TO semdo_wz;
-- 3. 授权
-- 3.1 指定表
GRANT SELECT ON schema_name.table_name TO semdo_wz;
-- 3.2 如果您希望用户具有访问所有表的权限,可以授予 ALL 权限。
GRANT SELECT ANY TABLE TO semdo_wz;
-- 4. 查询
sqlplus query_user/password@your_database
---- 查询表
SELECT * FROM SCHEMA_NAME.table_name; ## SCHEMA_NAME 指的是 用户SDT_YJWZ
GRANT SELECT ON SDT_YJWZ.material_code_relation TO semdo_wz;
GRANT SELECT ON SDT_YJWZ.material_sub_detail TO semdo_wz;
要为 semdo_wz 用户创建一个只具有查询功能的数据库用户,你需要按照以下步骤操作:
步骤 1:创建 semdo_wz 用户
首先,管理员需要在数据库中创建一个新用户 semdo_wz,并为该用户分配密码。你可以在 SQL*Plus 或者 SQL Developer 中使用以下命令:
CREATE USER semdo_wz IDENTIFIED BY password;
这里,password 是你为 semdo_wz 用户选择的密码。
步骤 2:授予连接和查询权限
接下来,你需要为 semdo_wz 用户授予必要的权限,以便它能够登录并执行查询。
授予连接权限: 使用户能够连接到数据库。
GRANT CONNECT TO semdo_wz;授予查询权限: 为了让
semdo_wz用户能够查询表数据,你需要授予SELECT权限。假设semdo_wz用户需要查询SDT_YJWZ用户下的表,你可以授予这些表的查询权限。如果你希望用户查询
SDT_YJWZschema 下的所有表,你可以执行如下命令(对于每个表):GRANT SELECT ON SDT_YJWZ.table_name TO semdo_wz;如果你希望为所有表授予查询权限,可以使用动态查询脚本:
BEGIN FOR r IN (SELECT table_name FROM all_tables WHERE owner = 'SDT_YJWZ') LOOP EXECUTE IMMEDIATE 'GRANT SELECT ON SDT_YJWZ.' || r.table_name || ' TO semdo_wz'; END LOOP; END;这段 PL/SQL 脚本会自动为
SDT_YJWZ用户下的所有表授予SELECT权限给semdo_wz用户。
步骤 3:可选 — 授予特定角色
如果你不想逐个表授予权限,也可以为 semdo_wz 用户分配一个角色,角色中包含所需的权限。
比如,创建一个角色并授予 SELECT 权限,然后将角色分配给 semdo_wz 用户:
创建角色:
CREATE ROLE query_role;授予角色查询权限:
GRANT SELECT ON SDT_YJWZ.table_name TO query_role;将角色分配给用户:
GRANT query_role TO semdo_wz;
步骤 4:测试用户权限
创建好 semdo_wz 用户并授予权限后,测试该用户是否能够登录并查询数据:
登录:
sqlplus semdo_wz/password@127.0.0.1:1521/orcl执行查询:**需要注意查询表的时候,需要带上用户名 **
SELECT * FROM SDT_YJWZ.table_name;
如果一切正常,semdo_wz 用户应该能够查询 SDT_YJWZ 用户下的表。
步骤 5:配置 JDBC
在你的 Java 应用程序中,你需要将数据库连接信息配置为使用 semdo_wz 用户。假设你的 jdbc.url 和数据库连接信息如下:
jdbc.url=jdbc:oracle:thin:@127.0.0.1:1521/orcl
jdbc.username=semdo_wz
jdbc.password=password
确保在 jdbc.username 和 jdbc.password 中使用 semdo_wz 用户的凭据。
总结
- 创建用户:使用
CREATE USER创建semdo_wz用户。 - 授予权限:授予连接权限和
SELECT权限。 - 配置 JDBC:在你的应用程序中更新数据库连接信息,使用
semdo_wz用户。
通过这些步骤,你将能够创建一个只具有查询权限的用户 semdo_wz,并配置其数据库连接。
oracle 删除表等并且释放空间
- 删除表、视图、索引等
BEGIN
-- 删除表
FOR r IN (SELECT table_name, owner FROM all_tables WHERE owner = 'SDT_ZHST_2024') LOOP
EXECUTE IMMEDIATE 'DROP TABLE ' || r.owner || '.' || r.table_name || ' CASCADE CONSTRAINTS';
END LOOP;
-- 删除视图
FOR r IN (SELECT view_name, owner FROM all_views WHERE owner = 'SDT_ZHST_2024') LOOP
EXECUTE IMMEDIATE 'DROP VIEW ' || r.owner || '.' || r.view_name;
END LOOP;
-- 删除索引
FOR r IN (SELECT index_name, owner FROM all_indexes WHERE owner = 'SDT_ZHST_2024') LOOP
EXECUTE IMMEDIATE 'DROP INDEX ' || r.owner || '.' || r.index_name;
END LOOP;
-- 删除存储过程、函数、包等
FOR r IN (SELECT object_name, object_type, owner FROM all_objects WHERE owner = 'SDT_ZHST_2024' AND object_type IN ('PROCEDURE', 'FUNCTION', 'PACKAGE')) LOOP
EXECUTE IMMEDIATE 'DROP ' || r.object_type || ' ' || r.owner || '.' || r.object_name;
END LOOP;
END;
/
- 删除用户
DROP USER SDT_ZHST_2024 CASCADE;
- 手动删除数据文件
如果删除表空间时仍然没有删除数据文件,您可以手动删除数据文件。要确保数据文件已经从表空间中移除,可以执行以下命令:
首先,使用
ALTER DATABASE命令将数据文件脱离表空间:ALTER DATABASE DATAFILE 'D:\app\lishihuan\oradata\orcl\SDT_ZHST_2024.DBF' OFFLINE;然后,删除数据文件:
HOST del D:\app\lishihuan\oradata\orcl\SDT_ZHST_2024.DBF;HOST命令用于在 SQL*Plus 中执行操作系统级别的命令,删除数据文件。
12. MySql
注: java 程序配置 MySql数据库时需要注意
mysql 权限:https://yunwei.blog.csdn.net/article/details/106424312
因为在mysql5中,jdbc的驱动是com.mysql.jdbc.Driver,
而mysql6以及以上是com.mysql.cj.jdbc.Driver
老板:
jdbc.type=mysql
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://192.168.2.149:3306/cpms_cz_dev?useUnicode=true&characterEncoding=utf-8&autoReconnect=true&failOverReadOnly=false&allowMultiQueries=true
jdbc.username=root
jdbc.password=root
?nullCatalogMeansCurrent=true 新版本-8:需要加 ?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone =Asia/Shanghai
jdbc.type=mysql
jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://192.168.2.149:3306/cpms_cz_dev?useUnicode=true&characterEncoding=utf-8&autoReconnect=true&failOverReadOnly=false&allowMultiQueries=true
#url: jdbc:mysql://localhost:3306/restful_crud?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone =Asia/Shanghai
jdbc.username=root
jdbc.password=root
xml文件中 & === > &
12.1 基本使用
cmd登陆:mysql -h 192.168.10.229 -p 9060 -uroot -pSemdo@123
查看数据库的语句是
SHOW DATABASES,查看数据库语法格式是:
SHOW DATABASES [LIKE '数据库名'];
mysql> SHOW DATABASES LIKE '%test%';
- 创建用户
CREATE USER 'lishihuan'@'172.16.10.229' IDENTIFIED BY '123456';
授权
删除用户
DROP USER 'lishihuan'@'172.16.10.229';
- 查询建表语句
SHOW CREATE TABLE table_name;
- 查询字段 属性
desc table_name;
- 切换数据库
use sdt_xjb;
删除表:
DROP TABLE my_table;删除数据(分场景,如果全删,用 truncate)
- 删除整表数据
truncate table my_table; - 删除部分数据
delete from my_table where id='1';
delete from sys_job_log; -- 遇到无法删除,因为磁盘存储空间满了 truncate table sys_job_log; optimize table sys_job_log;- 删除整表数据
查询进程
show processlist;
- 添加字段
## 表BAS_OP_TEAM 添加 字段LONGITUDE_GB 并且插入位置再PHONE字段后面
ALTER TABLE BAS_OP_TEAM ADD LONGITUDE_GB varchar(200) comment '所在位置经度(国标)' after PHONE;
ALTER TABLE OD_SHIFT_RECORD ADD `CODE` varchar(50) not null comment '班次CODE【唯一标识】' after START_DATE;
- 复制表结构
-- 备份表机构
create table yj_zhst_user_dept like yj_zhst_user ;
12.5 MySql ddl 语句
添加联合约束
ALTER TABLE climate_collect_pjrelation ADD unique(DEVICE_ID, ENGINEER_ID)
设置主键自增长
alter table workflow_leave modify id int auto_increment primary key;
alter table workflow_leave modify id int auto_increment;
删除时存在外键
使用delete 无法讲id自增长 序号清除
-- 禁用外键约束
SET FOREIGN_KEY_CHECKS = 0;
-- 执行 TRUNCATE 操作
TRUNCATE TABLE `yjydxj-cloud`.`emg_bus_imit_actv_matr_rec`;
-- 启用外键约束
SET FOREIGN_KEY_CHECKS = 1;
12.9 数据类型-整数
| 字段类型 | 名称 | 字节数 | 表示范围 |
|---|---|---|---|
| tinyint | 迷你整型 | 1个字节=8位 | 0-255 |
| smallint | 小整型 | 2个字节 | 0-65535 |
| mediumint | 中整型 | 3个字节 | - |
| int | 整型(标准整型) | 4个字节 | - |
| bigint | 大整型 | 8个字节 | - |
12.10 列转行
select a.id,a.name,a.label,substring_index(substring_index(a.value_item,';',b.help_topic_id+1),';',-1) value_item
from YH_BASE_DEAL_ARCH_CLASS a
join mysql.help_topic b on b.help_topic_id < (length(a.value_item) - length(replace(a.value_item,';',''))+1)
order by a.id;
12.20 内置函数
1. 空间查询 st_distance_sphere
效率高
SELECT st_distance_sphere(POINT(117.2649120808,31.9344120986),point(117.2594242812,31.9364424285))
自定义函数-空间计算
CREATE DEFINER=`root`@`%` FUNCTION `F_DISTANCE`(`cx` double,`cy` double,`sx` double,`sy` double) RETURNS double
begin
DECLARE d FLOAT(10,2);
DECLARE x FLOAT(10,2);
DECLARE y FLOAT(10,2);
DECLARE r FLOAT(10,2);
DECLARE pi FLOAT(10,2);
set r=6371229;
set pi=3.14159265358979323;
set x=(sx-cx)*pi*r*cos((sy+cy)/2*pi/180)/180;
set y=(sy-cy)*pi*r/180;
set d=SQRT(power(x,2)+power(y,2));
set D=ROUND(D,2);
RETURN d;
end
2. GREATEST()函数返回输入参数最大值
-- 查询'zt_time' , 'zy_time' , 'zn_time'中最大一个
SELECT
GREATEST(zt_time, zy_time, zn_time)
FROM
'XXX'
limit 取前多少条数据
select * from dw.dwd_sdxs_job_op limit 100;
空间函数,计算 坐标距离 (米)
计算地球两点之间的球面距离,单位为 米。传入的参数分别为X点的经度,X点的纬度,Y点的经度,Y点的纬度。
select st_distance_sphere(point(116.35620117,39.939093), point(116.4274406433,39.9020987219));
截取 substring 和 instr
select substring(hour_part,1,instr(hour_part,':')-1),hour_part from dw.dwd_sdxs_user_rec_hour h where to_days(data_dt)=to_days(now())
| hour | hour_part |
|---|---|
| 9 | 9:00-10:00 |
| 10 | 10:00-11:00 |
保留小数
select round(12.34345,2) -- 12.34
判断是否存在自定字符
case when LOCATE('±',l.volt_name)>0 then REPLACE(l.volt_name,'±','交流') else concat('直流',l.volt_name) end,
GREATEST()函数查找给定数字之间的最大数字。
SELECT GREATEST(10, 20, 30, 40, 50)
least 函数查找给定数字之间的最小数字。
SELECT least(10, 20, 30, 40, 50)
COALESCE
按照参数的顺序逐个评估参数,并返回第一个非空值
- 用途:
1)将控制替换成其他值;
2)返回第一个非空值
表达式
COALESCE是一个函数, (expression_1, expression_2, ...,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返回一个空值。使用COALESCE在于大部分包含空值的表达式最终将返回空值。
SQL实例
select coalesce(success_cnt, 1) from tableA
-- 以上写法将会判断certificate_file和labor_file字段是否为空,如果其中任意一个字段非空,则返回1,否则返回0。
SELECT CASE WHEN COALESCE(certificate_file, labor_file) IS NOT NULL THEN 1 ELSE 0 END as idPermitApply, a.* FROM zjjc_person a;
COALESCE()函数可以用来完成几乎所有的空值处理,不过在很多数据库系统中都提供了它的简化版,这些简化版中只接受两个变量,其参数格式如下: MYSQL: IFNULL(expression,value) MSSQLServer: ISNULL(expression,value) Oracle: NVL(expression,value)
这几个函数的功能和COALESCE(expression,value)是等价的。
比如SQL语句用于返回人员的“重要日期”,如果出生日期不为空则将出生日期做为“重要日期”,如果出生日期为空则返回注册日期的值:
-- MYSQL:
SELECT FBirthDay,FRegDay, IFNULL(FBirthDay,FRegDay) AS ImportDay FROM T_Person
-- MSSQLServer
SELECT FBirthDay,FRegDay, ISNULL(FBirthDay,FRegDay) AS ImportDay ROM T_Person
-- Oracle
SELECT FBirthDay,FRegDay, NVL(FBirthDay,FRegDay) AS ImportDay ROM T_Person
12.30 创建函数
set global log_bin_trust_function_creators=1;
如果创建的是带参 函数,需要给参数指定 类型同时指定大小,否则会报下面的错误
1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ')
CREATE DEFINER = CURRENT_USER FUNCTION `simpleFun`(name VARCHAR(20))
RETURNS varchar(30)
BEGIN
#Routine body goes here...
RETURN name;
END;
声明参数
drop function if exists hello;
-- a、b 都是函数的参数
create function hello(a varchar(20),b varchar(20)) returns varchar (255)
begin
-- declare 声明参数,default:设置声明参数的默认值
declare x varchar(255) default ' x ';
declare y varchar(255) default b;
declare c varchar(255) default ' 2017-01-02 ';
declare d varchar(255);
-- set 给声明的参数赋值
SET d = concat(x,a,b,y,c);
return d;
end;
12.40 定义变量
# 定义变量
set @dt = now();
select date_add(@dt, interval 1 day); -- add 1 day
select date_add(@dt, interval 1 hour); -- add 1 hour
# 赋值
set @:= 1;
select @dt:= @dt+3;
SELECT @dt:=5;
12.50 with as (创建临时表)
如果查询 报没有登陆数据库,可以通过 use DATABASES; 相当于先登陆一个数据库,创建的临时表就在 这个数据库下
with ydxj_ttsh_temp as -- ydxj_ttsh_temp 相当于一张临时表
(select t.line1_tower_id
from sdt_xjb.ydxj_ttsh t
)
select * from ydxj_ttsh_temp;
- 需要定义多个 临时表,可有用逗号相连, with xx as () , yy as ()
with temp1 as -- ydxj_ttsh_temp 相当于一张临时表
(select t.line1_tower_id
from table_name1 t
), temp2 as (
select * from table_name2
)
select * from temp1 p1
left join temp2 p2 on p1.id=p2.id;
12.60 组内排序
场景:要求显示每个部门年龄第二大的人
第一步,分组;第二步,组内按照年龄排序;第三步,组内排序后的数据加上序号
SELECT rownum, id, NAME, age, deptId, empno
FROM
(SELECT
(@i := #变量Qi的值,同一个部门内累加,部门变化则从0开始计数
CASE WHEN @deptId = deptId # 判断deptId是否发生变化
THEN @i + 1 #没有发生变化则将排序加1
ELSE 1 #发生变化则从1开始重新排序
END) rownum,t_emp.*,
( @deptId := deptId ) #将当前数据的部门号赋值给变量@deptId,即读取当前部门]的deptId号
FROM t_emp,
( SELECT @i := 0) AS a #定义变量并赋初值
GROUP BY deptId, id
ORDER BY deptId, age DESC # 年龄降序排列
) tb
WHERE rownum = 2 #年龄第几大,该处就写几
12.70 数据拉平,每条记录的上一条记录
查找每条巡视记录的上一次同类型的巡视
select op.opid,op.optime ,bb.pre_optime
from sdt_xjb.ydxj_job_op op
LEFT JOIN (
SELECT aa.major, aa.opobjid, aa.op_type, aa.optime,max(bb.optime) as pre_optime FROM
sdt_xjb.ydxj_job_op aa
left join sdt_xjb.ydxj_job_op bb ON bb.major = aa.major
AND bb.opobjid = aa.opobjid -- 找到当前每条记录的 前一条 巡视记录
AND bb.op_type = aa.op_type
AND bb.optime < aa.optime
group by aa.major, aa.opobjid, aa.op_type, aa.optime
) bb on bb.major=op.major and bb.opobjid=op.opobjid and bb.optime= op.optime
use sdt_xjb;
with act_hi_actinst_temp as ( -- 创建临时表
select ht.id_,ht.proc_inst_id_,ht.task_id_,act_id_,ht.act_name_,ht.start_time_,ht.end_time_,ht.duration_,ht.act_type_,
ROW_NUMBER() over(partition by ht.proc_inst_id_ order by ht.start_time_ ) as order_num
from sdt_xjb.act_hi_actinst ht
where
ht.act_type_ != 'exclusivegateway'
and ht.proc_inst_id_ in (
select distinct t.proc_inst_id_
from sdt_xjb.act_hi_actinst t
where t.proc_def_id_ like '%record_upgrades%'
and t.act_type_ != 'exclusivegateway'
and (date_format(t.start_time_, '%y-%m') = date_format(now(), '%y-%m') or date_format(t.end_time_, '%y-%m') = date_format(now(), '%y-%m'))
)
)
select
t1.id_ as id,
qx.id as record_id,-- 对应的缺陷id
t1.order_num,
t1.proc_inst_id_ as proc_inst_id ,
t1.act_type_ as node_type,
t1.act_name_ as curr_node_name,-- 当前节点名称
t2.act_name_ as next_node_name, -- 下个节点名称
hd.userId as user_id,
hd.userName as user_name,
t1.start_time_,
t1.end_time_,
t1.duration_,
hd.remark as remark
from act_hi_actinst_temp t1
left join act_hi_actinst_temp t2 on t1.proc_inst_id_=t2.proc_inst_id_ and t1.order_num=t2.order_num-1 -- 自己关联自己,获取每步的下个节点
inner join sdt_xjb.ydxj_danger_record qx on qx.proc_ins_id=t1.proc_inst_id_
-- 查审批过程 执行人和 备注
left join (select t.act_inst_id_,
max(case when t.name_='userId' then t.text_ else '' end) as userId,
max(case when t.name_='current' then t.text_ else '' end) as userName,
max(case when t.name_='remark' then t.text_ else '' end) as remark
from sdt_xjb.act_hi_detail t
group by t.act_inst_id_) hd
on hd.act_inst_id_=t1.id_
12.80 组内排序 开窗函数
-- 下例展示了按照property列分组对x列排名:
select x, y, dense_rank() over(partition by x order by y) as rank from int_t;
在MYSQL的最新版本MYSQL8已经支持了排名函数
RANK,DENSE_RANK和ROW_NUMBER。但是在就得版本中还不支持这些函数,只能自己实现。实现方法主要用到了条件判断语句(CASE WHEN或IF)和添加临时变量。但是8版本一下的无法使用,所以在排序取最新记录时,可有通过 下面2个方法
-- 说明: 通过时间存在不合理,毕竟不是唯一性,如果并发量大,这样就存在相同时间,会导致查询不准确,所以可以通过id来实现(前提id是自增长)
select t.*
from ydxj_dw_dwjl_2016 t
where dwsj = (
select max(t1.dwsj) from proj_base_trajectory t1 where t1.USERID = t.USERID
)
select a.*
from ydxj_dw_dwjl_2016 a
where not exists (select 1
from ydxj_dw_dwjl_2016 b
where b.userid = a.userid
and b.dwsj > a.dwsj)
1. 排名分类
1.1 区别RANK,DENSE_RANK和ROW_NUMBER
- RANK并列跳跃排名,并列即相同的值,相同的值保留重复名次,遇到下一个不同值时,跳跃到总共的排名。
- DENSE_RANK并列连续排序,并列即相同的值,相同的值保留重复名次,遇到下一个不同值时,依然按照连续数字排名。
- ROW_NUMBER连续排名,即使相同的值,依旧按照连续数字进行排名。
区别如图:

1.2 分组排名
将数据分组后排名,区别如图:

2. 准备数据
创建一张分数表,里面有字段:分数score,课程号course_id和学生号student_id。 执行如下SQL语句,进行导入数据。
create table score(
student_id varchar(10),
course_id varchar(10),
score decimal(18,1)
);
insert into score values('01' , '01' , 80);
insert into score values('01' , '02' , 90);
insert into score values('01' , '03' , 99);
insert into score values('02' , '01' , 70);
insert into score values('02' , '02' , 60);
insert into score values('02' , '03' , 80);
insert into score values('03' , '01' , 80);
insert into score values('03' , '02' , 80);
insert into score values('03' , '03' , 80);
insert into score values('04' , '01' , 50);
insert into score values('04' , '02' , 30);
insert into score values('04' , '03' , 20);
insert into score values('05' , '01' , 76);
insert into score values('05' , '02' , 87);
insert into score values('06' , '01' , 31);
insert into score values('06' , '03' , 34);
insert into score values('07' , '02' , 89);
insert into score values('07' , '03' , 98);
insert into score values('08' , '02' , 89);
insert into score values('09' , '02' , 89);
查看数据:

3. 不分组排名
3.1 连续排名
- 使用
ROW_NUMBER实现:
SELECT score,
ROW_NUMBER() OVER (ORDER BY score DESC) ranking
FROM score;
- 使用
变量实现:
SELECT s.score, (@cur_rank := @cur_rank + 1) ranking
FROM score s, (SELECT @cur_rank := 0) r
ORDER BY score DESC;
结果如图:

3.2 并列跳跃排名
- 使用
RANK实现:
SELECT course_id, score,
RANK() OVER(ORDER BY score DESC)
FROM score;
- 使用
变量和IF语句实现:
SELECT s.score,
@rank_counter := @rank_counter + 1,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @rank_counter) ranking,
@pre_score := s.score
FROM score s, (SELECT @cur_rank :=0, @pre_score := NULL, @rank_counter := 0) r
ORDER BY s.score DESC;
- 使用
变量和CASE语句实现:
SELECT s.score,
@rank_counter := @rank_counter + 1,
(
CASE
WHEN @pre_score = s.score THEN @cur_rank
WHEN @pre_score := s.score THEN @cur_rank := @rank_counter
END
) ranking
FROM score s, (SELECT @cur_rank :=0, @pre_score := NULL, @rank_counter := 0) r
ORDER BY s.score DESC;
结果如图:

3.3 并列连续排名
- 使用
DENSE_RANK实现:
SELECT course_id, score,
DENSE_RANK() OVER(ORDER BY score DESC) FROM score;
- 使用
变量和IF语句实现:
SELECT s.score,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1) ranking,
@pre_score := s.score
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL) r
ORDER BY s.score DESC;
- 使用
变量和CASE语句实现:
SELECT s.score,
(
CASE
WHEN @pre_score = s.score THEN @cur_rank
WHEN @pre_score := s.score THEN @cur_rank := @cur_rank + 1
END
) ranking
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL) r
ORDER BY s.score DESC;
结果如图:

4. 分组排名
4.1 分组连续排名
- 使用
ROW_NUMBER实现:
SELECT course_id, score,
ROW_NUMBER() OVER (PARTITION BY course_id ORDER BY score DESC) ranking FROM score;
- 使用
变量和IF语句实现:
SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id, @cur_rank := @cur_rank + 1, @cur_rank := 1) ranking,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank := 0, @pre_course_id := NULL) r
ORDER BY course_id, score DESC;
4.2 分组并列跳跃排名
- 使用
RANK实现:
SELECT course_id, score,
RANK() OVER(PARTITION BY course_id ORDER BY score DESC)
FROM score;
- 使用
变量和IF语句实现:
SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id,
@rank_counter := @rank_counter + 1,
@rank_counter := 1) temp1,
IF(@pre_course_id = s.course_id,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @rank_counter),
@cur_rank := 1) ranking,
@pre_score := s.score temp2,
@pre_course_id := s.course_id temp3
FROM score s, (SELECT @cur_rank := 0, @pre_course_id := NULL, @pre_score := NULL, @rank_counter := 1)r
ORDER BY s.course_id, s.score DESC;
4.3 分组并列连续排名
- 使用
DENSE_RANK实现:
SELECT course_id, score,
DENSE_RANK() OVER(PARTITION BY course_id ORDER BY score DESC)
FROM score;
- 使用
变量和IF语句实现:
SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1),
@cur_rank := 1) ranking,
@pre_score := s.score,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL, @pre_course_id := NULL) r
ORDER BY course_id, score DESC;
12345678
可以将上述的IF条件提取出来:
SELECT s.course_id, s.score,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1) temp1,
@pre_score := s.score temp2,
IF(@pre_course_id = s.course_id, @cur_rank, @cur_rank := 1) ranking,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL, @pre_course_id := NULL) r
ORDER BY course_id, score DESC;
普通写法
需求:每组的第一条数据
你可以使用MySQL中的GROUP BY子句和MIN()函数来实现这个目标。假设你想要根据字段UNIQUE_CODE查找每组的第一条数据,你可以按以下步骤执行:
SELECT *
FROM wl_work_op_rec
WHERE (UNIQUE_CODE, YOUR_DATE_FIELD) IN (
SELECT UNIQUE_CODE, MIN(YOUR_DATE_FIELD)
FROM wl_work_op_rec
GROUP BY UNIQUE_CODE
);
在这个查询中,你需要将YOUR_DATE_FIELD替换为你想要用来判断第一条数据的日期字段,比如时间戳或日期。这个查询首先在wl_work_op_rec表中找到每个UNIQUE_CODE对应的最小日期,然后将这些最小日期与对应的UNIQUE_CODE匹配,以获得每组的第一条数据。
案例:计算累计量
现在有个sql需要计算,计划和实施量 截至到每周的数量
select
TEAM_ID,TEAM_NAME,M_ID, M_NAME, S_ID,S_NAME,YEAR,WEEK_NUM,
plan_qty_W, OP_QTY_W, -- 计划量/实施量
CAST(PLAN_QTY_SUM_BY as UNSIGNED) PLAN_QTY_SUM_BY , -- 这里通过CAST 是因为mysql默认变量是double类型,所以计算的结果会有误差
CAST(OP_QTY_SUM_BY as UNSIGNED) OP_QTY_SUM_BY
from (
SELECT
TEAM_ID,TEAM_NAME,M_ID,M_NAME,S_ID,S_NAME,YEAR,WEEK_NUM,
plan_qty_W, -- 每周的计划量
OP_QTY_W, -- 每周的实施量
@cumulative_plan_qty_W := IF(@prev_group = CONCAT(TEAM_ID,'_', M_ID,'_', S_ID,'_', YEAR), @cumulative_plan_qty_W + plan_qty_W, plan_qty_W) AS PLAN_QTY_SUM_BY, -- 累计计划量
@cumulative_OP_QTY_W := IF(@prev_group = CONCAT(TEAM_ID,'_', M_ID,'_', S_ID,'_', YEAR), @cumulative_OP_QTY_W + OP_QTY_W, OP_QTY_W) AS OP_QTY_SUM_BY,-- 累计实施量
@prev_group := CONCAT(TEAM_ID,'_', M_ID,'_', S_ID,'_', YEAR) -- 用于分组,以 YJ站+主项工作+子项工作+年份,进行分组,然后累计 每个周次WEEK_NUM 下的计划和实施
from (SELECT @cumulative_plan_qty_W := 0, @cumulative_OP_QTY_W := 0, @prev_group := '') AS dummy,
WL_SUM_T_W_S a
) aa
order by TEAM_ID,TEAM_NAME,M_ID, M_NAME, S_ID,S_NAME,YEAR,WEEK_NUM -- 不用排序,这里只是用于方便查看数据的
12.90 mysql 对时间处理
常用日期处理,可以将其设置为 视图
create or replace view v_common_date as(
select
record_date,-- 获取今天凌晨
DATE_ADD(record_date,interval -day(record_date)+1 day) firstDay,-- 今天对应的所在月第一天
DATE_ADD(DATE_ADD(record_date,interval 1 month),interval -day(record_date)+1 day) as lastDay,-- 下个月第一天凌晨(也即本月最后一天)
yesterday,-- 昨天
tomorrow-- 明天
from(select a.record_date, -- 获取今天凌晨
date_add(a.record_date,INTERVAL -1 DAY ) as yesterday,-- 昨天
date_add(a.record_date,INTERVAL 1 DAY ) as tomorrow-- 明天
from (select FROM_UNIXTIME(UNIX_TIMESTAMP(CAST(NOW()AS DATE))) record_date) a -- 获取今天凌晨
)aa
)
| record_date | firstDay | lastDay | yesterday | tomorrow |
|---|---|---|---|---|
| 2022-04-06 00:00:00 | 2022-04-01 00:00:00 | 2022-05-01 00:00:00 | 2022-04-05 00:00:00 | 2022-04-07 00:00:00 |
select DATE_ADD(curdate(),interval -day(curdate())+1 day);-- 本月第一天 2022-04-01
select DATE_ADD(DATE_ADD(curdate(),interval 1 month),interval -day(curdate())+1 day);-- 下个月的第一天 2022-04-01
获取当前时间
select curdate(); -- 2021-03-02
select now(); -- 2021-03-02 11:52:56
-- 查看当天日期
select current_date(); -- 2021-03-03
-- 查看当天时间
select current_time(); -- 11:08:16
-- 查看当天时间日期
select current_timestamp();-- 2021-03-03 11:08:42
-- 获取当前时间的年份
select YEAR(now());
select MONTH(now());
返回日期在本年的第几天,范围为1到366。
SELECT DAYOFYEAR('2008-02-03'); # 34
SELECT DAYOFYEAR(now()); # 137
SELECT DAYOFYEAR(sysdate()); # 137
TIMESTAMPDIFF: MySql计算两日期时间之间相差的天数,秒数,分钟数,周数,小时数
语法为: TIMESTAMPDIFF(unit,datetime_expr1,datetime_expr2);
返回日期或日期时间表达式 datetime_expr1 和datetime_expr2the 之间的整数差。
其中unit单位有如下几种,分别是:FRAC_SECOND (microseconds), SECOND, MINUTE, HOUR, DAY, WEEK, MONTH, QUARTER, YEAR 。 该参数具体释义如下: FRAC_SECOND 表示间隔是毫秒 SECOND 秒 MINUTE 分钟 HOUR 小时 DAY 天 WEEK 星期 MONTH 月 QUARTER 季度 YEAR 年
例如:
#计算两日期之间相差多少周
select timestampdiff(week,'2011-09-30','2015-05-04');
#计算两日期之间相差多少天
select timestampdiff(day,'2011-09-30','2015-05-04');
另外计算两日期或时间之间相差多少天还可以使用 to_days 函数,但是该函数不用于阳历出现(1582)前的值,原因是当日历改变时,遗失的日期不会被考虑在内。因此对于1582 年之前的日期(或许在其它地区为下一年 ), 该函数的结果实不可靠的。具体用法如:
to_days(end_time) - to_days(start_time);
#计算两日期/时间之间相差的秒数:
select timestampdiff(SECOND,'2011-09-30','2015-05-04');
另外还可以使用 MySql 内置函数 UNIX_TIMESTAMP 实现,如下:
SELECT UNIX_TIMESTAMP(end_time) - UNIX_TIMESTAMP(start_time);
#计算两日期/时间之间相差的时分数:
select timestampdiff(MINUTE,'2011-09-30','2015-05-04');
另外还可以如下实现:
SELECT SEC_TO_TIME(UNIX_TIMESTAMP(end_time) - UNIX_TIMESTAMP(start_time));
注:
相差多少天 可以使用 to_days 函数
to_days(end_time) - to_days(start_time);或者使用 DATEDIFF 函数:
SELECT DATEDIFF('2020-01-13','2018-10-01');相差的秒数 可以使用 UNIX_TIMESTAMP 函数:
SELECT UNIX_TIMESTAMP(end_time) - UNIX_TIMESTAMP(start_time);相差分支数 可以使用 SEC_TO_TIME 函数:
SELECT SEC_TO_TIME(UNIX_TIMESTAMP(end_time) - UNIX_TIMESTAMP(start_time));now() 函数返回的是当前时间的年月日时分秒,如:2008-12-29 16:25:46;
CURDATE() 函数返回的是年月日信息: 如:2018-6-17
**CURTIME()**函数返回的是当前时间的时分秒信息,如:22:50
格式化时间:包含年月日时分秒日期格式化成年月日日期,可以使用DATE(time)函数,如DATE(now()) 返回的是 2018-6-17
说明:需要格式化时间并且还要求不改变date格式的就可以用
select DATE('2021-02-12 00:00:00') 如果时间格式字符串
date_format(now(), '%Y%m%d')unix_timestamp(日期,format) 把日期转化为时间戳 到秒的
CURDATE() 获取的时间虽然和DATE(now()) 看起来一样,但实际值不一样。
案例
-- 1.查看当天日期
select current_date();
-- 2、 查看当天时间
select current_time();
-- 3、查看当天时间日期
select current_timestamp();
-- 4、查询当天记录
select * from 表名 where to_days(时间字段名) = to_days(now());
-- 5、查询昨天记录
select * from 表名 where to_days( now( ) ) – to_days( 时间字段名) <= 1
-- 6、查询7天的记录
select * from 表名 where date_sub(curdate(), interval 7 day) <= date(时间字段名)
-- 7、查询近30天的记录
select * from 表名 where date_sub(curdate(), interval 30 day) <= date(时间字段名)
-- 8、查询本月的记录
select * from 表名 where date_format( 时间字段名, '%y%m' ) = date_format( curdate( ) , '%y%m' )
-- 9、查询上一月的记录
select * from 表名 where period_diff( date_format( now( ) , '%y%m' ) , date_format( 时间字段名, '%y%m' ) ) =1
-- 10、查询本季度数据
select * from 表名 where quarter(create_date)=quarter(now());
-- 11、查询上季度数据
select * from 表名 where quarter(create_date)=quarter(date_sub(now(),interval 1 quarter));
-- 12、查询本年数据
select * from 表名 where year(create_date)=year(now());
-- 13、查询上年数据
select * from 表名 where year(create_date)=year(date_sub(now(),interval 1 year));
-- 14、查询当前这周的数据
select * from 表名 where yearweek(date_format(submittime,'%y-%m-%d')) = yearweek(now());
-- 15、查询上周的数据
select * from 表名 where yearweek(date_format(submittime,'%y-%m-%d')) = yearweek(now())-1;
-- 16、查询当前月份的数据
select * from 表名 where date_format(submittime,'%y-%m')=date_format(now(),'%y-%m')
-- 17、查询距离当前现在6个月的数据
select name,submittime from enterprise where submittime between date_sub(now(),interval 6 month) and now();
-- 获取本月第一天
select DATE_ADD(curdate(),interval -day(curdate())+1 day)
-- 获取当月最后一天
select last_day(curdate());
-- 获取下个月的第一天
select date_add(curdate()-day(curdate())+1,interval 1 month )
-- 获取当前月的天数
select DATEDIFF(date_add(curdate()-day(curdate())+1,interval 1 month ),DATE_ADD(curdate(),interval -day(curdate())+1 day)) from dual
注:spring-mvc 中,SQlMap 再是用获取本月第一天时引用以下语句 :
SELECT DATE_ADD(CURDATE(),INTERVAL 1-DAYOFMONTH(CURDATE()) DAY); -- 获取本月第一天
Mysql 获取昨日、今日、明日凌晨时间 ,本月第一天,今年第一天
https://blog.csdn.net/qq_40058321/article/details/102224125
# 获取今日凌晨时间
UNIX_TIMESTAMP(CAST(SYSDATE()AS DATE))
# 获取昨日凌晨时间
UNIX_TIMESTAMP(CAST(SYSDATE()AS DATE) - INTERVAL 1 DAY)
# 获取明日凌晨时间
UNIX_TIMESTAMP(CAST(SYSDATE()AS DATE) + INTERVAL 1 DAY)
# 获取的是时间戳
# 时间戳转换成datetime, datetime也就是我们说的日期格式 年-月-日 时-分-秒
FROM_UNIXTIME();
# datetime转时间戳
UNIX_TIMESTAMP();
# 测试
SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(CAST(SYSDATE()AS DATE))) 今日;-- 2019-10-06 00:00:00
SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(CAST(SYSDATE()AS DATE) - INTERVAL 1 DAY)) 昨日;-- 2019-10-05 00:00:00
SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(CAST(SYSDATE()AS DATE) + INTERVAL 1 DAY)) 明日;-- 2019-10-07 00:00:00
# 本月第一天
select DATE_ADD(curdate(),interval -day(curdate())+1 day)
-- 今年第一天
SELECT DATE_FORMAT(DATE_SUB(CURDATE(),INTERVAL dayofyear(now())-1 DAY),'%Y-%m-%d') AS c_year
-- 去年第一天
SELECT DATE_FORMAT((DATE_SUB((DATE_SUB(NOW(),INTERVAL dayofyear(now())-1 DAY)),INTERVAL 1 YEAR)),'%Y-%m-%d') AS last_year
格式化日期 DATE_FORMAT
# DATE_FORMAT(datetime ,format)用法,转换日期格式
DATE_FORMAT('2019-10-07 00:00:00', '%Y-%c-%d');-- 2019-10-07
# 常用的:
# '%Y-%c-%d %H:%i:%S'
# 年-月-日 时:分:秒
# '%Y-%c-%d'
# 年-月-日
# '%H:%i:%S'
# 时:分:秒
可以使用的格式有:
| 格式 | 描述 |
|---|---|
| %a | 缩写星期名 |
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时 (00-23) |
| %h | 小时 (01-12) |
| %I | 小时 (01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天 (001-366) |
| %k | 小时 (0-23) |
| %l | 小时 (1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T | 时间, 24-小时 (hh:mm:ss) |
| %U | 周 (00-53) 星期日是一周的第一天 |
| %u | 周 (00-53) 星期一是一周的第一天 |
| %V | 周 (01-53) 星期日是一周的第一天,与 %X 使用 |
| %v | 周 (01-53) 星期一是一周的第一天,与 %x 使用 |
| %W | 星期名 |
| %w | 周的天 (0=星期日, 6=星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与 %V 使用 |
| %x | 年,其中的星期一是周的第一天,4 位,与 %v 使用 |
| %Y | 年,4 位 |
| %y | 年,2 位 |
eg:
SELECT
id,
DATE_FORMAT(create_time, '%Y-%c-%d %H:%i:%S')
FROM epc_mes_item
WHERE create_time = '2018-11-19 23:00:20';
SELECT
id,
DATE_FORMAT(create_time, '%Y-%c-%e')
FROM epc_mes_item
WHERE DATE_FORMAT(create_time, '%Y-%c-%d') >= '2018-11-19';
date_add 、DATE_SUB 固定时间加 天,小时
- date_add
select date_add(日期, interval 1 day); 日期加天
select date_add(日期, interval 1 hour); 日期加小时
select date_add(日期, interval 1 minute); 日期加分
select date_add(日期, interval 1 second);日期加秒
select date_add(日期, interval 1 microsecond); 日期加微秒
select date_add(日期, interval 1 week); 日期加周
select date_add(日期, interval 1 month); 日期加月
select date_add(日期, interval 1 quarter); 日期加季度
select date_add(日期, interval 1 year); 日期加年
- DATE_SUB
SELECT * FROM 表名 WHERE 时间字段>DATE_SUB(CURDATE(), INTERVAL 1 YEAR) 一年
SELECT * FROM 表名 WHERE 时间字段>DATE_SUB(CURDATE(), INTERVAL 1 WEEK) 一周
SELECT * FROM 表名 WHERE 时间字段 >DATE_SUB(CURDATE(), INTERVAL 3 MONTH) 三个月
1、当前日期
select DATE_SUB(curdate(), INTERVAL 0 DAY) ;
2、明天日期
select DATE_SUB(curdate(), INTERVAL -1 DAY) ;
3、昨天日期
select DATE_SUB(curdate(), INTERVAL 1 DAY) ;
4、前一个小时时间
select date_sub(now(), interval 1 hour);
5、后一个小时时间
select date_sub(now(), interval -1 hour);
6、前30分钟时间
select date_add(now(), interval -30 minute)
7、后30分钟时间
select date_add(now(), interval 30 minute)
使用按理:
select a.record_date, -- 获取今天凌晨
date_add(a.record_date,INTERVAL -1 DAY ) as yesterday,-- 昨天
date_add(a.record_date,INTERVAL 1 DAY ) as tomorrow-- 明天
from (select FROM_UNIXTIME(UNIX_TIMESTAMP(CAST(NOW()AS DATE))) record_date) a -- 获取今天凌晨
use sdt_xjb;
with record_date_temp as (-- 用来事先 定义好 当前凌晨,用于过滤时间
select record_date,
DATE_ADD(record_date,interval -day(record_date)+1 day) monthFirstDay,-- 今天对应的所在月第一天
yesterday,-- 昨天
tomorrow-- 明天
from(select a.record_date, -- 获取今天凌晨
date_add(a.record_date,INTERVAL -1 DAY ) as yesterday,-- 昨天
date_add(a.record_date,INTERVAL 1 DAY ) as tomorrow-- 明天
from (select FROM_UNIXTIME(UNIX_TIMESTAMP(CAST(NOW()AS DATE))) record_date) a -- 获取今天凌晨
) aa
)
select * from record_date_temp
12.92 时间查询
AND a.op_date LIKE concat( DATE_FORMAT(CURDATE(), '%Y-%m'), '%' )
12.93 查询本月每天
- 查询当月的每一天,由1号开始,到当月结束日期
SELECT
date_add(DATE_ADD(curdate(), INTERVAL - DAY(curdate()) + 2 DAY), INTERVAL (cast( help_topic_id AS signed INTEGER ) - 1 ) DAY ) DAY
from mysql.help_topic
where help_topic_id < day(last_day(curdate()))
order by help_topic_id
- 查询当天起未来一个月(30天)的每一天
select
date_add(curdate(), interval(cast(help_topic_id as signed integer) ) day) day
from mysql.help_topic
where help_topic_id < day(last_day(curdate()))
order by help_topic_id
Mysql中Cast()函数的用法
Cast(字段名 as 转换的类型 ),其中类型可以为:字符类型转换
| CHAR | 字符型 |
| DATE | 日期型 |
| DATETIME | 日期和时间型 |
| DECIMAL | float型(没测试出来效果) |
| SIGNED | int |
| TIME | 时间型 |
-- CHAR 字符型
select cast('2022-07-13 18:16:29' as DATE) ; -- 2022-07-13
select cast('2022-07-13 18:16:29' as DATETIME) ; -- 2022-07-13 18:16:29
select cast('2022-07-13 18:16:29' as TIME) ; -- 18:16:29
select cast('2022-07-13 18:16:29' as char); -- 2022-07-13 18:16:29;
select cast('2022-07-13 18:16:29' as DECIMAL) ; -- 2022
select cast('2022-07-13 18:16:29' as SIGNED) ; -- 2022
-- MySQL 中的变量来计算累计值。由于变量默认是 double 类型,对于一些小数运算可能会出现舍入误差
select CAST(74.000000000000000000000 AS UNSIGNED); -- 74
12.100MySql 对小数的处理
- round 函数,四舍五入
select round(12.34512,3) -- 12.345
FLOOR 表示向下取整,只返回值X的整数部分,小数部分舍弃
CEILING 表示向上取整,只返回值X的整数部分,小数部分舍弃。
12.110 MySQL
longtext类型 不能用 is null 来 实现过滤 为空的字段 使用函数: length(xx) =0 来过滤数据
select * from t_restree k where length(k.c_extended) =0;
12.120 根据不同维度 对数据汇总,行转列 的一种写法
场景:ads_sdxs_index_day表根据 巡视类型 专业、专项 记录每天 的应巡、已巡、人巡、无人机巡视的次数。现在需要统计,专业、专项、全部、人巡、机巡 巡视完成率
- 数据源:
SELECT
major_id,-- 巡视类型(1:专业2:专项)
major_name,
todo_xscs,-- 应巡
done_xscs_month,-- 已巡
rg_done_xscs_month,-- 人工巡视
wrj_done_xscs_month-- 无人机巡视
-- round( done_xscs_month / todo_xscs * 100, 2 ) AS wcl
FROM ads.ads_sdxs_index_day
WHERE TO_DAYS( data_dt )= TO_DAYS(now())
| 巡视类型id | 巡视类型 | 应巡 | 已巡 | 人工巡视 | 无人机巡视 |
|---|---|---|---|---|---|
| 2 | 专项巡视 | 54401 | 107662 | 107662 | 0 |
| 1 | 专业巡视 | 18212 | 17287 | 12857 | 4430 |
- 效果:需要统计,专业、专项、全部、人巡、机巡 巡视完成率
select
CONCAT(zy_wcl,'%') as zy_wcl,
CONCAT(zx_wcl,'%') as zx_wcl,
CONCAT(all_wcl,'%') as all_wcl,
CONCAT(jx_wcl,'%') as jx_wcl,
CONCAT(rx_wcl,'%') as rx_wcl,
done_xscs_month,todo_xscs
from (select
sum(case when major_id =1 then wcl else 0 end )as zy_wcl,/*专业巡视*/
sum(case when major_id =2 then wcl else 0 end )as zx_wcl,/*专项巡视*/
round(sum(done_xscs_month)/sum(todo_xscs)*100,2) as all_wcl,/*总巡视*/
round(sum(rg_done_xscs_month)/sum(todo_xscs)*100,2) as rx_wcl,/*人工巡视*/
round(sum(wrj_done_xscs_month)/sum(todo_xscs)*100,2) as jx_wcl,/*无人机巡视*/
sum(done_xscs_month) done_xscs_month,
sum(todo_xscs) todo_xscs
from(
select major_id,major_name,todo_xscs,done_xscs_month,rg_done_xscs_month,wrj_done_xscs_month, round(done_xscs_month/todo_xscs*100,2) as wcl
FROM ads.ads_sdxs_index_day WHERE TO_DAYS( data_dt )= TO_DAYS(now())
) aa
)a
| zy_wcl(专业巡视完成率) | zx_wcl(专项巡视完成率) | all_wcl(巡视完成率) | jx_wcl(人巡完成率) | rx_wcl(机巡完成率) | done_xscs_month(巡视次数) | todo_xscs(应巡次数) |
|---|---|---|---|---|---|---|
| 94.92% | 197.9% | 172.08% | 6.09% | 165.99% | 124949 | 72613 |
12.125 使用LIMIT 分组
注意事项,需要对写的sql 添加 order by ,否则会查询失败
12.126
SELECT * from bas_tower where FIND_IN_SET(id, '623,23');
12.127 mysql排序字段为空的排在最后面
oracle 可以通过 实现oracle的nulls [first|last] 实现
select *from (
select -1 sort_num ,start_device from BAS_LINE_EXT where id=81
union all
select null sort_num ,end_device from BAS_LINE_EXT where id=81
)aa
order by sort_num is null,sort_num
12.130
**left join中 由于 没有和主表关联,导致 使用 逻辑运算符(> = <)出错 **
SELECT
m.tower_id,m.tower_name, m.tower_no,m.line_id,m.line_name,m.section_id,m.section_name
FROM dw.dwd_sdxs_plan_month m
LEFT JOIN (
SELECT op.major,op.tower_id,
count(1) AS done_xscs
FROM dw.dwd_sdxs_job_op op
WHERE date_format( op.op_time, '%Y-%m' ) = date_format( now(), '%Y-%m' )
GROUP BY op.major, op.tower_id
) c ON c.major = m.major AND c.tower_id = m.tower_id
WHERE date_format( m.data_dt, '%Y-%m' ) = date_format( now(), '%Y-%m' )
AND m.todo_xscs > 0
AND todo_xscs > ifnull(done_xscs,0) /* 获取 应巡大于已巡的次数的记录*/
/**
AND todo_xscs > ifnull(done_xscs,0) 而不能 用 AND todo_xscs > done_xscs
因为 left join 可能没关联上,顾使用 AND todo_xscs > done_xscs 导致 针对done_xscs 为null 的记录被忽略
所以 使用 AND (todo_xscs > done_xscs or done_xscs is null)
或者 AND todo_xscs > ifnull(done_xscs,0) 都行
*/
批量修改
update DS_BASE_ORG_RULE r
left join DS_BASE_ORG_RULE r1 on r.id=(r1.id+1)
set r.start_time =r1.start_time , r.end_time=r1.end_time, r.name=r1.name
where r.id>10;
批量查询
<select id="selectAllItemsByIds" parameterType="java.util.List" resultMap="BaseResultMap">selectid, field1, field2from item_info<where>id in<foreach collection="list" item="item" open="(" separator="," close=")">#{item}</foreach></where>
</select>
批量删除
<delete id="deleteUsersByNames" parameterType="java.util.List">delete from item_infowhere username in<foreach collection="list" item="item" open="(" separator="," close=")">#{item}</foreach>
</delete>
批量更新
<update id="updateItemsById"><foreach collection="list" item="item" index="index" open="" close="" separator=";">UPDATE item_info<set>field1 = #{item.field1}</set>WHERE id = #{id}</foreach>
</update>
<insert id="updateInsert">
<foreach collection="list" item="item" index="index" open="" close="" separator=";">
update bas_line_contrast
<set >
<if test="item.secretName != null" >
secret_name = #{item.secretName,jdbcType=VARCHAR},
</if>
</set>
where id = #{item.id}
</foreach>
</insert>
<update id="updateMateriaStatus">
UPDATE zjjc_material_info
SET
<foreach collection="list" item="item" open="sh_state = case id" close="END">
WHEN #{item.materialId} THEN #{item.shState}
</foreach>
WHERE id IN
<foreach collection="list" item="item" separator="," open="(" close=")">
<if test="item.materialId != null">
#{item.materialId}
</if>
</foreach>
</update>
批量插入
<insert id="insertItemsByBatch" parameterType="java.util.List">insert into item_info (id,field1,field2)values<foreach collection="list" item="item" index="index" separator=",">(#{item.id,jdbcType=BIGINT},#{item.field1,jdbcType=VARCHAR},#{item.field2,jdbcType=VARCHAR})</foreach>
</insert>
- 支持批量插入后返回主键id,针对父子表的情况
navicat 获取ddl 语句

2.
Navicat 导出和导入数据库
http://mylishihuan.gitee.io/web_book/src/java/数据库/MySql卸载和安装.html
linux下开启、关闭、重启mysql服务
https://blog.csdn.net/weixin_44708715/article/details/90702843
通过:SHOW VARIABLES LIKE "%char%"; 查询文件位置
一、 启动
1、使用 service 启动:service mysql start 2、使用 mysqld 脚本启动:/etc/inint.d/mysql start 3、使用 safe_mysqld 启动:safe_mysql&
二、停止
1、使用 service 启动:service mysql stop 2、使用 mysqld 脚本启动:/etc/inint.d/mysql stop 3、mysqladmin shutdown
三、重启
1、使用 service 启动:service mysql restart 2、使用 mysqld 脚本启动:/etc/inint.d/mysql restart
注:如果启动报下面的错误,可以使用: systemctl start mysqld
[root@bgtest01 mysql]# service mysql start
Redirecting to /bin/systemctl start mysql.service
mysql 忽略大小写
# Copyright (c) 2014, 2021, Oracle and/or its affiliates.
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License, version 2.0,
# as published by the Free Software Foundation.
#
# This program is also distributed with certain software (including
# but not limited to OpenSSL) that is licensed under separate terms,
# as designated in a particular file or component or in included license
# documentation. The authors of MySQL hereby grant you an additional
# permission to link the program and your derivative works with the
# separately licensed software that they have included with MySQL.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License, version 2.0, for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
#
# The MySQL Server configuration file.
#
# For explanations see
# http://dev.mysql.com/doc/mysql/en/server-system-variables.html
[mysqld]
lower_case_table_names=1
log-bin=mysql-bin
server-id=1
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
#log-error = /var/log/mysql/error.log
# By default we only accept connections from localhost
#bind-address = 127.0.0.1
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
event_scheduler=1
skip-grant-tables
max_connections=2000
group_concat_max_len=10240000
default-time-zone='+08:00'
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
mysql ifnull 判断空字符
varchar 字段不为null,此时无法使用ifnull

如果为null --> IFNULL(a,b) a 为null 则 取b
如果为空:ifnull(if(length(trim(字段))>0,字段,null),'1') num
小数的处理
99.9999 输出 99.9999
99.0000 输出 99
select 0+cast(90.9999 as char ); -- 90.9999
select 0+cast(90.0000 as char ); -- 90
select 0+cast(ifnull(字段,0) as char ); -- 90
常见异常
#### sql injection violation, comment not allow
sql 中添加的注释,导致执行失败
查询 大表
-- information_schema
select table_name,table_rows from tables order by table_rows desc ;
15.50 初始化异常
echarts 无法获取属性“getAttribute”的值: 对象为 null 或未定义 错误解决方法
造成这种错误的原因是
echarts.js引用放在head中或者放在body中HTML代码的前面了,造成加载时阻塞后面的html。
解决方法就是将echarts.js的引用放在
</body>之前就可以了
创建 函数报错
1418 - This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you might want to use the less safe log_bin_trust_function_creators variable)
原因 MySQL开启bin-log后,调用存储过程 或者函数以及触发器时,会出现错误号为1418的错误:
详细说明:
这是我们开启了bin-log, 我们就必须指定我们的函数是否是 1 DETERMINISTIC 不确定的 2 NO SQL 没有SQl语句,当然也不会修改数据 3 READS SQL DATA 只是读取数据,当然也不会修改数据 4 MODIFIES SQL DATA 要修改数据 5 CONTAINS SQL 包含了SQL语句
**解决:**创建子程序(存储过程、函数、触发器)时,声明为DETERMINISTIC或NO SQL与READS SQL DATA中的一个,就是在begin关键在之前声明,我这里声明为DETERMINISTIC
解决不了 空字符串
select number_convert(12.345) ; -- 12.345 select number_convert(12.00) ; -- 12 select number_convert(10) ; -- 10 select number_convert('10.00') ; -- 10 select number_convert(null) ; -- 0 select number_convert('') ;-- Data truncated for column 'str' at row 1
-- 解决 小数的问题
CREATE FUNCTION number_convert (str double) RETURNS double
DETERMINISTIC -- 添加这行,否则无法添加
begin
DECLARE d double;
set d= 0+cast(ifnull(str,0) as char );
RETURN d;
end
if 的写法
begin
IF num is not null THEN
RETURN 0+cast(ifnull(num,0) as char );
ELSEIF xxxxx THEN
RETURN xxx;
ELSE
RETURN 0;
END IF;
end
函数
- 判断是否为数值
CREATE DEFINER=`root`@`%` FUNCTION `isnumeric`(`str` int) RETURNS int(1)
BEGIN
DECLARE temp int(1);
DECLARE hasSqlError int DEFAULT FALSE;
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET hasSqlError=TRUE;
set temp = to_number(str);
IF hasSqlError THEN
RETURN 0;
ELSE
RETURN 1;
END IF;
END
从身份证中拿到年纪
CREATE FUNCTION CalculateAgeFromIdentity(identity VARCHAR(18))
RETURNS INT
BEGIN
DECLARE age INT;
IF identity REGEXP '^[0-9]{17}[0-9X]$' THEN
SET age = YEAR(CURDATE()) - YEAR(STR_TO_DATE(SUBSTRING(identity, 7, 8), '%Y%m%d')) - (RIGHT(CURDATE(), 5) < RIGHT(STR_TO_DATE(SUBSTRING(identity, 7, 8), '%Y%m%d'), 5));
ELSE
SET age = NULL;
END IF;
RETURN age;
END
存储过程
递归
这个查询会从指定的起始
menu_id(例如 2338)开始,逐级查找其子菜单
SELECT DISTINCT t1.*
FROM sys_menu t1
JOIN (
SELECT * FROM (
SELECT * FROM sys_menu
ORDER BY menu_id, parent_id
) AS t2
JOIN (
SELECT @pv := '2338' -- 设置起始 menu_id
) AS t3
WHERE FIND_IN_SET(parent_id, @pv) > 0
AND @pv := CONCAT(@pv, ',', menu_id)
) AS t4 ON t1.menu_id = t4.menu_id;
案例使用
1) 场景:检测设备状态
设备有效期 validity_date 如果小于今天,则算为超期
如果在30内,则算为 预警
否则数据正常
UPDATE zjjc_material_info
SET EFFE_STATE =
CASE
WHEN validity_date < CURDATE() THEN '03' -- 超期
WHEN DATEDIFF(validity_date, CURDATE()) <= 30 THEN '02' -- 预警
ELSE '01' -- 有效
END
查询每张表的大小
SELECT
table_name AS '表名',
round((( data_length + index_length ) / 1024 / 1024 ), 2 ) AS '大小(MB)'
FROM information_schema.TABLES
WHERE table_schema = 'yjydxj-cloud'
ORDER BY ( data_length + index_length ) DESC;
提示时间格式不对 1292
MySQL #1292 – Incorrect date value: ‘0000-00-00’
打开mysql目录下的my.ini文件,找到sql-mode /etc/my.conf
sql_mode="STRICT_ALL_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE,NO_AUTO_CREATE_USER
将NO_ZERO_DATE,NO_ZERO_IN_DATE,删掉保存重启mysql即可
systemctl start mysqld # 启动
systemctl restart mysqld;
systemctl stop mysqld; ## 关闭
MySQL日志
场景:需要查看mysql的插入语句,通过日志来观察,sql的执行
额外补充:如果考虑到日志文件太大,可以删除,然后重新创建 再执行
mysql -u root -pSemdo@2021 -e "FLUSH LOGS;"刷新日志保证日志的重新写入
- 使用
mysql -u yourusername -p命令来登录,其中yourusername是你的MySQL用户名。 - 启用查询日志。你可以使用
SET GLOBAL general_log = 'ON';命令来启动查询日志。(临时开启) - 检查日志文件的位置。执行
SHOW VARIABLES LIKE 'general_log_file';,你会看到日志文件的路径。 - 使用
tail -f /path/to/your/logfile命令来查看日志文件,其中/path/to/your/logfile是你的日志文件路径。这个命令会显示日志文件的最新内容。 - 对于插入语句,你可以在日志文件中搜索
INSERT关键字
查询大表
SELECT
table_schema AS `Database`,
table_name AS `Table`,
ROUND(SUM(data_length + index_length) / 1024 / 1024, 2) AS `Size_MB`
FROM
information_schema.tables
WHERE
table_schema = 'yjydxj-cloud' -- 用你自己的数据库名替换
-- and table_name='sys_job_log'
GROUP BY
table_schema, table_name
ORDER BY
`Size_MB` DESC;
- 删除表并且释放空间
TRUNCATE TABLE xxx;
执行表迁移卡死,定位到:未提交的事务阻塞 导致
通过 下面的查询 找出异常的阻塞的事务
SELECT * FROM information_schema.INNODB_TRX
WHERE trx_state = 'RUNNING'; -- 可以查询出 trx_id
通过 trx_id 进行关闭
-- 终止事务(替换为实际的 trx_id)
KILL 事务ID_1;
如果失败 通过 SHOW PROCESSLIST; 找出相应的进程
SHOW PROCESSLIST;
# 通过 进程id 进行关闭
KILL 进程id; -- 替换为实际存在的 ID
关于 ON DUPLICATE KEY UPDATE 的解释
能实现INSERT 不用考虑是是否已经存在的问题,如果存在执行update
在之前的代码中,ON DUPLICATE KEY UPDATE 是用来处理插入时主键冲突的情况的。如果历史表中已经存在某条记录(例如主键 ID 冲突),则会执行更新操作,而不是插入重复记录。
示例:
sql浅色版本
INSERT INTO OD_ROUND_RECORD_HIS (ID, DEL_FLAG, UPDATE_DATE)
VALUES (123, 1, NOW())
ON DUPLICATE KEY UPDATE
DEL_FLAG = VALUES(DEL_FLAG),
UPDATE_DATE = VALUES(UPDATE_DATE);
- 如果
ID = 123的记录在历史表中不存在,则插入新记录。 - 如果
ID = 123的记录在历史表中已存在,则更新DEL_FLAG和UPDATE_DATE字段。
MyBatis
集合:<if test="arr != null and arr.size() > 0">
数组:<if test="col != null and col.length > 0">
<!-- 批量修改-->
<update id="batchUpdate">
<foreach collection="zjjcPersonList" item="item" index="index" open="" close="" separator=";">
UPDATE zjjc_person
<trim prefix="SET" suffixOverrides=",">
<if test="item.empNo != null">emp_no = #{item.empNo},</if>
<if test="item.name != null">name = #{item.name},</if>
<if test="item.sex != null">sex = #{item.sex},</if>
<if test="item.year != null">year = #{item.year},</if>
<if test="item.phone != null">phone = #{item.phone},</if>
</trim>
WHERE id = #{item.id}
</foreach>
</update>
<!-- 批量新增-->
<insert id="batchInsert">
insert into zjjc_person( emp_no,name,sex,year,phone )
values
<foreach collection="zjjcPersonList" separator="," item="item">
( #{item.empNo},#{item.name},#{item.sex},#{item.year},#{item.phone} )
</foreach>
</insert>
<update id="updateMateriaStatusOfSuccess">
UPDATE zjjc_material_info
SET
is_filings = '1',
sh_state = '0',
<foreach collection="list" item="item" open="certificate = case id" close="end">
WHEN #{item.materialId} THEN #{item.testFileCode}
</foreach>
,
<foreach collection="list" item="item" open="certificate_file = case id" close="end">
WHEN #{item.materialId} THEN #{item.testFile}
</foreach>
,
<foreach collection="list" item="item" open="validity_date = case id" close="end">
WHEN #{item.materialId} THEN #{item.validityDate}
</foreach>
WHERE id IN
<foreach collection="list" item="i" separator="," open="(" close=")">
#{i.materialId}
</foreach>
</update>
<if test="ids != null ">
and a.id in
<foreach item="id" collection='ids.split(",")' open="(" separator="," close=")">
#{id}
</foreach>
</if>
concat
concat 如果拼接的项中有空,则返回空
concat( u.name, a.telephone) AS extData1, -- 如果telephone 为空,则 整个返回空
-- 正确写法
concat( u.name, IFNULL(a.telephone,'') ) AS extData1,
<select id="selectByFileIds" resultMap="...">
SELECT * FROM table_name
<where>
<if test="fileIds != null and fileIds.size() > 0">
AND file_id IN
<foreach item="item" collection="fileIds" open="(" separator="," close=")">
#{item}
</foreach>
</if>
</where>
</select>
17 java
idea 修改 maven配置后,肯能出现 项目报错,重启,清楚缓存都不能正常编译,手动刷新maven

查找pom用的jar https://mvnrepository.com/
jar包冲突https://blog.csdn.net/noaman_wgs/article/details/81137893
17.1 事物
参考网址 : https://blog.csdn.net/zhou_java_hui/article/details/53302278
场景1: A类方法,调用B类b方法,如果b异常,想通过try catch 来自定义异常,不进行事物回滚
@Transactional(
//propagation=Propagation.NESTED,
propagation= Propagation.NESTED,
rollbackFor={Exception.class}
)
public void b(){
// b方法
}
17.2 HttpClient4.x进行Get/Post请求并使用ResponseHandler处理响应
导包
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.4</version>
</dependency>
<!--StringUtil-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>${commons-lang3.version}</version>
</dependency>
<!--java.net-->
<dependency>
<groupId>commons-net</groupId>
<artifactId>commons-net</artifactId>
<version>1.4.1</version>
</dependency>
<!--http客户端-->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.4</version>
</dependency>
17.3 Java获取 当前访问的服务路径
String url = request.getRequestURL().toString();
String baseUrl =url.substring(0,url.indexOf("/a/"));
17.4 获取当前ip&MAC地址
https://www.jb51.net/article/121571.htm
/**
* 获得用户远程地址
*/
public static String getRemoteAddr(HttpServletRequest request){
String remoteAddr = request.getHeader("X-Real-IP");
if (isNotBlank(remoteAddr)) {
remoteAddr = request.getHeader("X-Forwarded-For");
}else if (isNotBlank(remoteAddr)) {
remoteAddr = request.getHeader("Proxy-Client-IP");
}else if (isNotBlank(remoteAddr)) {
remoteAddr = request.getHeader("WL-Proxy-Client-IP");
}
return remoteAddr != null ? remoteAddr : request.getRemoteAddr();
}
17.6 java @ResponseBody返回值中去掉NULL字段
https://www.cnblogs.com/zhangpengshou/p/5630723.html
需要同时添加两个位置:
- 1、annotation-driven过滤
<mvc:annotation-driven>
<mvc:message-converters register-defaults="true">
<bean class="org.springframework.http.converter.json.MappingJackson2HttpMessageConverter">
<property name="objectMapper">
<bean class="com.fasterxml.jackson.databind.ObjectMapper">
<property name="dateFormat">
<bean class="java.text.SimpleDateFormat">
<constructor-arg type="java.lang.String" value="yyyy-MM-dd HH:mm:ss" />
</bean>
</property>
<property name="serializationInclusion">
<util:constant static-field="com.fasterxml.jackson.annotation.JsonInclude.Include.NON_NULL" />
</property>
</bean>
</property>
</bean>
</mvc:message-converters>
</mvc:annotation-driven>
- RequestMapping过滤
<bean class="org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter">
<property name="messageConverters">
<list>
<bean class="org.springframework.http.converter.json.MappingJackson2HttpMessageConverter">
<property name="objectMapper">
<bean id="jacksonObjectMapper" class="com.fasterxml.jackson.databind.ObjectMapper">
<property name="dateFormat">
<bean class="java.text.SimpleDateFormat">
<constructor-arg type="java.lang.String" value="yyyy-MM-dd HH:mm:ss" />
</bean>
</property>
<property name="serializationInclusion">
<util:constant static-field="com.fasterxml.jackson.annotation.JsonInclude.Include.NON_NULL" />
</property>
</bean>
</property>
<property name="supportedMediaTypes">
<list>
<value>application/json;charset=UTF-8</value>
<value>application/x-www-form-urlencoded</value>
</list>
</property>
</bean>
<bean class="org.springframework.http.converter.ByteArrayHttpMessageConverter">
<property name="supportedMediaTypes">
<list>
<value>image/jpeg</value>
<value>image/png</value>
</list>
</property>
</bean>
</list>
</property>
</bean>
springboot 的处理方式
https://www.cnblogs.com/qinxu/p/10208858.html
spring:
# jackson时间格式化
jackson:
time-zone: GMT+8
date-format: yyyy-MM-dd HH:mm:ss
default-property-inclusion: non_null
17.10java之 Timer 类的简单使用案例
Timer来讲就是一个调度器 ,类似于js中的 定时器setInterval
阻塞
public static void main(String[] args) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for (int i = 0; i < 3; i++) {
try {
Thread.sleep(5 * 1000); //设置暂停的时间 5 秒
System.out.println(sdf.format(new Date()) + "--循环执行第" + (i+1) + "次");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
17.20 List转为String
public static String listToString(List list, char separator) {
return StringUtils.join(list.toArray(), separator);
}
/**
将transmissionHis.getCollectTypes() 拆分开,分为2个字段
*/
public void collectTypeClassified(TransmissionHis transmissionHis){
if(StringUtils.isNotEmpty(transmissionHis.getCollectTypes())){
String[] collectTypeArr = transmissionHis.getCollectTypes().split(",");
List<String> collectTypelist = Lists.newArrayList();// 收藏
List<String> deviceTypelist = Lists.newArrayList();// 设备
for (String collectType: collectTypeArr) {
if("14".equals(collectType)||"16".equals(collectType)){
deviceTypelist.add(collectType);
}else{
collectTypelist.add(collectType);
}
}
transmissionHis.setCollectTypes(listToString(collectTypelist,','));
transmissionHis.setDevicetypes(listToString(deviceTypelist,','));
}
}
17.30 java对时间处理
/**
* 获取本月的第一天和最后一天的日期,输出格式例如20160801,
* 其中第一天的key为firstDay,最后一天的key为lastDay
* @return dateMap
* @author Gavin Ma
*/
public static Map<String, String> getCurrentMonthFEDay() {
Map<String, String> dateMap = new HashMap<String, String>();
SimpleDateFormat format = new SimpleDateFormat("yyyyMMdd");
//获取前月的第一天
Calendar cal_1=Calendar.getInstance();//获取当前日期
cal_1.add(Calendar.MONTH, -1);
cal_1.set(Calendar.DAY_OF_MONTH,1);//设置为1号,当前日期既为本月第一天
String firstDay = format.format(cal_1.getTime());
//获取前月的最后一天
Calendar cale = Calendar.getInstance();
cale.set(Calendar.DAY_OF_MONTH,0);//设置为1号,当前日期既为本月第一天
String lastDay = format.format(cale.getTime());
dateMap.put("firstDay", firstDay);
dateMap.put("lastDay", lastDay);
return dateMap;
}
计算2个时间段的交集时长
public static void main(String[] args) {
long l = calculateOverlap("7:00", "9:00", "9:12", "9:30");
System.out.println(l);
}
public static long calculateOverlap(String start1Str, String end1Str, String start2Str, String end2Str) {
// 创建一个DateTimeFormatter来解析没有秒的时间
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("H:mm");
// 使用formatter将字符串转化为LocalTime对象
LocalTime start1 = LocalTime.parse(start1Str, formatter);
LocalTime end1 = LocalTime.parse(end1Str, formatter);
LocalTime start2 = LocalTime.parse(start2Str, formatter);
LocalTime end2 = LocalTime.parse(end2Str, formatter);
// 计算交叉时长
LocalTime overlapStart = start1.isAfter(start2) ? start1 : start2;
LocalTime overlapEnd = end1.isBefore(end2) ? end1 : end2;
if (overlapStart.isBefore(overlapEnd)) {
return Duration.between(overlapStart, overlapEnd).toMinutes();
} else {
return 0;
}
}
17.100 file
场景:文件的导出
- 以流的形式输出到浏览器导出文件
- 指定盘符导出
// 1.指定盘符导出,简单格式
public static void excelTest0() throws IOException {
//创建HSSFWorkbook对象
HSSFWorkbook wb = new HSSFWorkbook();
//创建HSSFSheet对象
HSSFSheet sheet = wb.createSheet("sheet0");
//创建HSSFRow对象
HSSFRow row = sheet.createRow(0);
//创建HSSFCell对象
HSSFCell cell=row.createCell(0);
//设置单元格的值
cell.setCellValue("单元格中的中文");
//输出Excel文件
FileOutputStream output=new FileOutputStream("d:\\workbook.xls");
wb.write(output);
output.flush();
}
//2. B/S模式中采用的输出方式,而不是输出到本地指定的磁盘目录。该代码表示将details.xls的Excel文件通过应答实体(response)输出给请求的客户端浏览器,客户端可保存或直接打开。
public static String excelTest2(HttpServletRequest request,HttpServletResponse response) throws IOException{
//创建HSSFWorkbook对象
HSSFWorkbook wb = new HSSFWorkbook();
//创建HSSFSheet对象
HSSFSheet sheet = wb.createSheet("sheet0");
//创建HSSFRow对象
HSSFRow row = sheet.createRow(0);
//创建HSSFCell对象
HSSFCell cell=row.createCell(0);
//设置单元格的值
cell.setCellValue("单元格中的中文");
//输出Excel文件
OutputStream output=response.getOutputStream();
response.reset();
response.setHeader("Content-disposition", "attachment; filename=details.xls");
response.setContentType("application/msexcel");
wb.write(output);
output.close();
return null;
}
17.110 用map对数据进行分类统计
1)案例1.用一个字段作为统计条件(以设备名称)
业务场景:大批量的导入设备,要求导入的数据中设备名称不能重复,所以要对导入的所以数据进行判断,看是否有重复
Map<String, List<NvrDevice>> map=new HashMap<String, List<NvrDevice>>();//=========NvrDevice为要导入的对象,将对象放到map里面,同时将设备名称作为map的key
===========这样就会将同一个key的对象放到同一个map中的list对象里
===========map里面存放多条不同key组成的键值对,,一个key 是 nvrName 讲相同的key的NvrDevice 合并再一起,塞在list中
//用来判断导入的数据中'名称'是否存在重复
for (NvrDevice nvrDevice2 : nvrDeviceList) {
if(!map.containsKey(nvrDevice2.getNvrName())){//============containsKey是用来判断某个key是否存在
map.put(nvrDevice2.getNvrName(), new ArrayList<NvrDevice>());//=====不存在就新new一个map对象,并将此时的设备名称作为key存入。
}
map.get(nvrDevice2.getNvrName()).add(nvrDevice2);//==最后map存放的就是唯一key的list对象,而list对象中可能存再设备名称相同的NvrDevice对象
}
for (String nvrName : map.keySet()) {//======================以key来遍历map集合
if(map.get(nvrName).size()>1){//=======================表示对于设备名称的存在多条
for (NvrDevice nvrDevice3 : map.get(nvrName)) {
nvrDevice3.setResult(nvrDevice3.getResult()+nvrName+"有重复的;");
}
}
}
///=========================================验证导入数据是否存在重复,============================================
List<String> nameList=new ArrayList<String>()
for(NvrDevice nvrDevice2 : nvrDeviceList){//遍历对象,取除name,如果list里面没有,那么就将name 放到list里面,如果有表示存在重复
String name= nvrDevice2.getNvrName();
if (names.contains(fileName)) {// Java中list集合ArrayList 中contains包含的使用
//说明存在
}
nameList.add(name);
}
2)案例2:
业务场景:服务商领用备品备件--存在自己的库存中使用,最后登记已经使用的数量。(所以思路是:以服务商和备件名来统计,具有相同的服务商和备件分别统计出,出库的量和已经使用的量)

//gcywBpbjCkRecord是出库记录 以他为主表。将具有相同的服务商和备件的使用量放到对应的出库记录中(相应的出库记录中增加一个存放使用量的字段)
public String fwsStock(GcywBpbjCkRecord gcywBpbjCkRecord, Model model){
//一。获取对应服务商--备件的出库量(通过服务商和备件这两个条件去分类统计库存量分别是多少)
List<GcywBpbjCkRecord> listData=new ArrayList<GcywBpbjCkRecord>();//最后存放数据的,将具有相同服务商--备件的记录中的数据存放在其中一个
List<GcywBpbjCkRecord> list=gcywBpbjCkRecordService.findList(gcywBpbjCkRecord);//获取所有的信息
for (GcywBpbjCkRecord fws : list) {
if(!mapFws.containsKey(fws.getBcampany())){//通过服务商来第一层统计
mapFws.put(fws.getBcampany(), new HashMap<String, List<GcywBpbjCkRecord>>());
}
if(mapFws.containsKey(fws.getBcampany())){
if(!mapFws.get(fws.getBcampany()).containsKey(fws.getBpbjId())){
mapFws.get(fws.getBcampany()).put(fws.getBpbjId(), new ArrayList<GcywBpbjCkRecord>());
}
mapFws.get(fws.getBcampany()).get(fws.getBpbjId()).add(fws);
}
}
for(String fwsName:mapFws.keySet()){
for (String bpbjName : mapFws.get(fwsName).keySet()) {
Double num=0.0;
for (GcywBpbjCkRecord ckRecord : mapFws.get(fwsName).get(bpbjName)) {
num+=ckRecord.getBpbjNum();//=========1.数据中农具有相同服务商--备件的对象都存放在一个map中,然后遍历,将出库量的记录累加
}
//============2。将统计后的数据赋值给list中的第一个对象,作为有效数据listData.add(mapFws.get(fwsName).get(bpbjName).get(0));
mapFws.get(fwsName).get(bpbjName).get(0).setBpbjNum(num);
}
}
System.out.println(listData);
//二。从使用记录中获取对应服务商--备件使用的实际量
List<GcywBpbjUseSituation> listData2=new ArrayList<GcywBpbjUseSituation>();
Map<String,List<GcywBpbjUseSituation>> map2=new HashMap<String, List<GcywBpbjUseSituation>>();
Map<String,Map<String,List<GcywBpbjUseSituation>>> mapFws2=new HashMap<String, Map<String,List<GcywBpbjUseSituation>>>();
List<GcywBpbjUseSituation> list2 = gcywBpbjUseSituationService.findList(new GcywBpbjUseSituation());
for (GcywBpbjUseSituation fws : list2) {
if(!mapFws2.containsKey(fws.getFwsId())){
mapFws2.put(fws.getFwsId(), new HashMap<String, List<GcywBpbjUseSituation>>());
}
if(mapFws2.containsKey(fws.getFwsId())){
if(!mapFws2.get(fws.getFwsId()).containsKey(fws.getBpbjId())){
mapFws2.get(fws.getFwsId()).put(fws.getBpbjId(), new ArrayList<GcywBpbjUseSituation>());
}
mapFws2.get(fws.getFwsId()).get(fws.getBpbjId()).add(fws);
}
}
for(String fwsName:mapFws2.keySet()){
for (String bpbjName : mapFws2.get(fwsName).keySet()) {
Double num=0.0;
for (GcywBpbjUseSituation gcywBpbjUse : mapFws2.get(fwsName).get(bpbjName)) {
num+=gcywBpbjUse.getBpbjNumber();
}
mapFws2.get(fwsName).get(bpbjName).get(0).setBpbjNumber(num);
listData2.add(mapFws2.get(fwsName).get(bpbjName).get(0));
}
}
//三。用来整合上面的2个map集合,将实际使用量在写到对应的出库记录中
Map<String,Map<String, GcywBpbjUseSituation>> maps=new HashMap<String, Map<String,GcywBpbjUseSituation>>();
for (GcywBpbjUseSituation fws : listData2) {
if(!maps.containsKey(fws.getFwsId())){
maps.put(fws.getFwsId(), new HashMap<String, GcywBpbjUseSituation>());
}
if(maps.containsKey(fws.getFwsId())){
if(!maps.get(fws.getFwsId()).containsKey(fws.getBpbjId())){
maps.get(fws.getFwsId()).put(fws.getBpbjId(), fws);
}
}
}
for(GcywBpbjCkRecord ckRecord :listData){
if(maps.containsKey(ckRecord.getBcampany())){
if(maps.get(ckRecord.getBcampany()).containsKey(ckRecord.getBpbjId())){
System.out.println(maps.get(ckRecord.getBcampany()).get(ckRecord.getBpbjId()).getBpbjNumber());
ckRecord.setBpbjNumber(maps.get(ckRecord.getBcampany()).get(ckRecord.getBpbjId()).getBpbjNumber());
}
}
}
System.out.println(listData2);
model.addAttribute("gcywBpbjCkRecord",gcywBpbjCkRecord);
model.addAttribute("listData",listData);
return "modules/gcyw/gcywBpbjFwsStock";
}
在java中所有的map都实现了Map接口,因此所有的Map(如HashMap, TreeMap, LinkedHashMap, Hashtable等)都可以用以下的方式去遍历。
方法一:在for循环中使用entries实现Map的遍历:
/**
* 最常见也是大多数情况下用的最多的,一般在键值对都需要使用
*/
Map <String,String>map = new HashMap<String,String>();
map.put("熊大", "棕色");
map.put("熊二", "黄色");
for(Map.Entry<String, String> entry : map.entrySet()){
String mapKey = entry.getKey();
String mapValue = entry.getValue();
System.out.println(mapKey+":"+mapValue);
}
方法二:在for循环中遍历key或者values,一般适用于只需要map中的key或者value时使用,在性能上比使用entrySet较好;
Map <String,String>map = new HashMap<String,String>();
map.put("熊大", "棕色");
map.put("熊二", "黄色");
//key
for(String key : map.keySet()){
System.out.println(key);
}
//value
for(String value : map.values()){
System.out.println(value);
}
方法三:通过Iterator遍历;
Iterator<Entry<String, String>> entries = map.entrySet().iterator();
while(entries.hasNext()){
Entry<String, String> entry = entries.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+":"+value);
}
方法四:通过键找值遍历,这种方式的效率比较低,因为本身从键取值是耗时的操作;
for(String key : map.keySet()){
String value = map.get(key);
System.out.println(key+":"+value);
}
17.120 生成json 文件
- 指定盘符生成json文件
- map对数据的 处理
/**
根据 不同电压 等级,组装 地图需要的线路数据
List<LineVO> lineList = findLineByIds(towerVO);
查询出来的数据是利用resultMap 构成 线路--GT 结构(线路pojo对象 包含一个GT的List集合)
遍历结果集: 利用map讲同一个电压等级下的线路合并到一起。最后再遍历这个map,生成不同电压等级下的 线路json文件
例如:35KV.json
[{
"type": "Feature",
"geometry": {
"type": "LineString",
"coordinates": [[118.5705817,31.00465868],[118.5715242,31.00233154],[118.5722901,31.00044132],......]
},
"properties": {
"ID":"ys500sdwsdsidjqsxian",
"NAME":"35kV吉泉线接地极",
"voltageGrade":"35kV"
}
}]
**/
public String createLineFileForMap(TowerVO towerVO) throws Exception {
String filePath = "";
try {
List<LineVO> lineList = findLineByIds(towerVO);
filePath = SettingUtils.getCfgSettingByCodeForSelf("platform_address").getValue()+"/lineDataFor3DMap/data";// 指定导出文件
/**
* json 格式中 第一层 线路组成的数组
* 每个线路对象 3个参数,第一个type 类型
* 第二个 坐标信息 geometry,又分为 2个对象,第一个是 type='LineString'类型 ,第二个是 坐标信息 [[],[],[]......]
* 第三个 属性信息properties
* 需要以每个不同 电压等级 创建一个 对于的JSON 文件,然后把 同一个电压等级下的线路组装在一起,再写入到该json文件中
*/
Map<String,JSONArray> voltageGradeMap=Maps.newHashMap();
//JSONArray lineJsonList = new JSONArray();
for (LineVO lineVO:lineList) {
//============containsKey是用来判断某个key是否存在
if(!voltageGradeMap.containsKey(lineVO.getVoltageGrade())){
//=====不存在就新new一个map对象,并将此时的设备名称作为key存入。
voltageGradeMap.put(lineVO.getVoltageGrade(), new JSONArray());
}
//1.组装第一层 type='Feature'
JSONObject lineObject = new JSONObject();
lineObject.put("type","Feature");//
//2. 线路属性信息(计划存储,电压等级,线路id,线路名称)
JSONObject linePropertiesObject = new JSONObject();
linePropertiesObject.put("ID",lineVO.getLineId());// 线路id
linePropertiesObject.put("NAME",lineVO.getLineName());
linePropertiesObject.put("linePmsid",lineVO.getLinePmsid());
linePropertiesObject.put("voltageGrade",lineVO.getVoltageGrade());
lineObject.put("properties",linePropertiesObject);// 线路 属性 信息
//3.坐标信息
JSONArray coordinatesList = new JSONArray();
for (TowerVO tower: lineVO.getTowerList()) {
JSONArray towerPointList = new JSONArray();
towerPointList.add(0,Float.parseFloat(tower.getLongitudeGps()));// 经度
towerPointList.add(1,Float.parseFloat(tower.getLatitudeGps()));// 纬度
coordinatesList.add(towerPointList);
}
// 组装 坐标信息
JSONObject geometryObject = new JSONObject();
geometryObject.put("type","LineString");
geometryObject.put("coordinates",coordinatesList);
lineObject.put("geometry",geometryObject);
//lineJsonList.add(lineObject);
voltageGradeMap.get(lineVO.getVoltageGrade()).add(lineObject);
}
System.out.println(voltageGradeMap);
for(String key : voltageGradeMap.keySet()){
JSONArray lineJsonList = voltageGradeMap.get(key);
createJsonFile(lineJsonList,filePath+"/"+key+".json");
}
logger.info("##==三维地图生成不同电压等级下的线路JSON文件===="+"导出线路成功:"+filePath);
} catch (Exception e) {
e.printStackTrace();
logger.error("##==三维地图生成不同电压等级下的线路JSON文件===="+"导出线路失败:"+e);
throw new Exception("文件生成失败"+e);
}
System.out.println("线路JSON文件生成完成!");
return filePath;
}
/**
* 将JSON数据格式化并保存到文件中
* @param jsonData 需要输出的json数
* @param filePath 输出的文件地址
* @return
*/
public static boolean createJsonFile(Object jsonData, String filePath) {
String content = JSON.toJSONString(jsonData, SerializerFeature.PrettyFormat, SerializerFeature.WriteMapNullValue,
SerializerFeature.WriteDateUseDateFormat);
// 标记文件生成是否成功
boolean flag = true;
// 生成json格式文件
try {
// 保证创建一个新文件
File file = new File(filePath);
if (!file.getParentFile().exists()) { // 如果父目录不存在,创建父目录
file.getParentFile().mkdirs();
}
if (file.exists()) { // 如果已存在,删除旧文件
file.delete();
}
file.createNewFile();
// 将格式化后的字符串写入文件
Writer write = new OutputStreamWriter(new FileOutputStream(file), "UTF-8");
write.write(content);
write.flush();
write.close();
} catch (Exception e) {
flag = false;
e.printStackTrace();
}
return flag;
}
17.125 java io
//获取指定的文件夹下的所有pdf 文件
public static ArrayList<String> getFiles(String path) {//D:\myEclipse\apache-tomcat-7_myElipse\apache-tomcat-7.0.73\webapps\SDT_IMOA\//work/zip/20190424163926/LA-R-2019-012-万善昆-1000kV圩淮Ⅰ线
ArrayList<String> files = new ArrayList<String>();
File file = new File(path);
File[] tempList = file.listFiles();
for (int i = 0; i < tempList.length; i++) {
if (tempList[i].isFile()) {
String fileName = tempList[i].getName();//获取文件名
String fileType=fileName.substring(fileName.lastIndexOf(".")+1);//获取文件的后缀名
if("pdf".equals(fileType)||"PDF".equals(fileType)){
files.add(tempList[i].toString());
}
}
}
System.out.print("文 件:" + files);
return files;
}
17.126 Java IO 创建文件解决文件名重复问题
文件名在操作系统中不允许出现 / \ ” : | * ? < > 故将其以空替代
**注:**文件创建时需要注意
- 名称特殊字符(例如 \ 会导致文件被当作文件夹截取 )
- 文件名称重复
Pattern pattern = Pattern.compile("[\\s\\\\/:\\*\\?\\\"<>\\|]");
Matcher matcher = pattern.matcher(fileName);
fileName= matcher.replaceAll(""); // 将匹配到的非法字符以空替换
两个思路:
1.定义一个全局变量Map,以文件名称为key,序号为value. 调用方法前,先初始化map,因为全局变量,防止历史对数据的影响。方法调用需要传递fileName,判断当前文件名对应的key是否存在,如果存在则value+1,并拼好名称,返回
2.传递一个路径,判断文件是否存在,循环,直到文件名称没有重复返回
- 方法1:
/**
* 防止文件名称重复,导致java io 读写失败
* 考虑有些 是 添加到 压缩包中,所以无法通过 io 来验证是否存在
* @param filePath
* @param fileName
* @return
* List<String> fileNameList=new ArrayList<String>();// 防止文件名重复 导致 程序异常,故需对 每个 文件名进行判断
*/
public static String getFileNameByList(List<String> fileNameList, String fileName){
fileName = StringEscapeUtils.unescapeHtml(fileName);
Matcher matcher = pattern.matcher(fileName);//判断是否存在特殊字符 做空字符串替换
fileName= matcher.replaceAll(""); // 将匹配到的非法字符以空替换
//文件名,如spring
String name = fileName.substring(0,fileName.indexOf("."));
//文件后缀,如.jpeg
String suffix = fileName.substring(fileName.lastIndexOf("."));
int i = 1;
//若文件存在重命名
while(fileNameList.contains(fileName)) {
String newFilename = name+"("+i+")"+suffix;
i++;
fileName=newFilename;
}
return fileName;
}
- 方法2:
// 防止文件名称重复,导致java io 读写失败
public String getFileName(String fileName,String filePath){
//源文件
File descFile = new File(filePath+ File.separator+fileName);
int i = 1;
//若文件存在重命名
while(descFile .exists()) {
String newFilename = fileName+"("+i+")";
descFile = new File(filePath+ File.separator+newFilename);
i++;
}
return fileName;
}
package practice.IO;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @author 言曌
* @date 2017/12/2 上午10:59
*/
public class Demo {
/**
* 将 /Users/liuyanzhao/Desktop/spring.jpeg 文件
* 拷贝到 /Users/liuyanzhao/Desktop/io/中
* 需要避免文件名重复覆盖的情况
*/
public static void main(String args[]) throws IOException {
//源文件
File sourceFile = new File("/Users/liuyanzhao/Desktop/spring.jpeg");
//文件的完整名称,如spring.jpeg
String filename = sourceFile.getName();
//文件名,如spring
String name = filename.substring(0,filename.indexOf("."));
//文件后缀,如.jpeg
String suffix = filename.substring(filename.lastIndexOf("."));
//目标文件
File descFile = new File("/Users/liuyanzhao/Desktop/io"+File.separator+filename);
int i = 1;
//若文件存在重命名
while(descFile.exists()) {
String newFilename = name+"("+i+")"+suffix;
String parentPath = descFile.getParent();
descFile = new File(parentPath+ File.separator+newFilename);
i++;
}
descFile.createNewFile(); //新建文件
FileInputStream fin = new FileInputStream(sourceFile);
FileOutputStream fout = new FileOutputStream(descFile);
byte[] data = new byte[512];
int rs = -1;
while((rs=fin.read(data))>0) {
fout.write(data,0,rs);
}
fout.close();
fin.close();
}
}
17.127 java 生成文件
--------------待整理:js分公司 附件上传
以流的形式传递到前端,执行下载,后端可有用重定向,这样可以 通过addMessage(redirectAttributes, "导出失败!"); 返回前端报错提示
https://blog.csdn.net/weixin_44176169/article/details/105320502 (单文件,多文件上传 MultipartFile 、MultipartHttpServletRequest )
仿阿里云的写法,讲需要上传的附件,分为,“上传字符串”,“上传Byte数组”,“上传网络流”,"本地附件" https://help.aliyun.com/document_detail/84781.html?spm=a2c4g.11186623.6.961.5a7c16906I5hsl
// 填写网络流地址。
InputStream inputStream = new URL("https://www.aliyun.com/").openStream();
已流的形式 浏览器输出
指定盘符 生成本地文件
通过url 下载附件
public static String getRelativeFilePath(String fileName, String rootDirPath, String relativePath){
//判断是否存在特殊字符 做空字符串替换
Matcher matcher = pattern.matcher(fileName);
//URLEncoder.encode(newFileName,"UTF-8");//针对中文乱码
fileName= matcher.replaceAll(""); // 将匹配到的非法字符以空替换
/**
* 判断附件上传,指定位置的文件夹是否存在
*/
File saveDirFile = new File(rootDirPath+File.separator+relativePath);//E:/CPMS/CPMS_FILES/CPMS_JSFGS/proj/20200426/lihuan
if (!saveDirFile.exists()) {//不存在指定文件夹 先创建
saveDirFile.mkdirs();
}
return relativePath+File.separator+fileName;// 文件的相对路径(用于返回结果)
}
/**
* 将url 资源 下载到本地,并返回 相对路径
* 调用者 在使用时需要 自己补上 rul前缀 Global.getConfig("towerViewImg")+filePath
* @param URL
* @param rootDirPath :文件上传根目录 E:/CPMS/CPMS_FILES/CPMS_JSFGS
* @param relativePath:文件所在 文件夹相对路径 /proj/20200426/lihuan
* @return
* @throws Exception
*/
public static String uploadFileByURL(String URL,String rootDirPath,String relativePath) throws Exception {
//文件名
String fileName=URL.substring(URL.lastIndexOf("/")+1);
String relativeFilePath=getRelativeFilePath(fileName,rootDirPath,relativePath);// 获取相对路径,用于 返回给 前端
java.net.URL url = new URL(URL);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setConnectTimeout(6000);
urlCon.setReadTimeout(6000);
int code = urlCon.getResponseCode();
if (code != HttpURLConnection.HTTP_OK) {
throw new Exception("文件读取失败");
}
//读文件流
DataInputStream in = new DataInputStream(urlCon.getInputStream());
DataOutputStream out = new DataOutputStream(new FileOutputStream(rootDirPath+File.separator+relativeFilePath));
byte[] buffer = new byte[2048];
int count = 0;
while ((count = in.read(buffer)) > 0) {
out.write(buffer, 0, count);
}
out.close();
in.close();
relativeFilePath = relativeFilePath.replaceAll("\\\\", "/");
return "/" + relativeFilePath;
}
打包下载( 通过url 下载文件 案例是 通过 oss需要整理成 普通url)
不生成 本地文件,直接以流的形式输出
public static void downForZipAsFlowByOSS(HttpServletRequest req, HttpServletResponse response,List<String> fileUrlList, String fileName ){
// 创建临时文件
File zipFile = null;
try {
//临时文件名称
zipFile = File.createTempFile("downZipTemp", ".zip");
FileOutputStream f = new FileOutputStream(zipFile);
/**
* 作用是为任何OutputStream产生校验和
* 第一个参数是制定产生校验和的输出流,第二个参数是指定Checksum的类型 (Adler32(较快)和CRC32两种)
*/
CheckedOutputStream csum = new CheckedOutputStream(f, new Adler32());
// 用于将数据压缩成Zip文件格式
ZipOutputStream zos = new ZipOutputStream(csum);
AliOssClient aliOssClient= createAliOssClient();
OSS ossClient = aliOssClient.getOssClient();
String bucket_domain_url = SettingUtils.getCfgSettingByCode("BUCKET_DOMAIN_URL").getValue();
for (String ossFile : fileUrlList) {
// 路径前面 加 ‘/’ 会导致下载失败,所以需要 判断然后剔除掉多余的 /
ossFile = getRelativeFilePthByOSS(ossFile);
// 获取Object,返回结果为OSSObject对象
OSSObject ossObject = ossClient.getObject(aliOssClient.getBucketName(),ossFile);//bucket_domain_url
// 读去Object内容 返回
InputStream inputStream = ossObject.getObjectContent();
// 对于每一个要被存放到压缩包的文件,都必须调用ZipOutputStream对象的putNextEntry()方法,确保压缩包里面文件不同名
String name=ossFile.substring(ossFile.lastIndexOf("/")+1);
zos.putNextEntry(new ZipEntry(name));
int bytesRead = 0;
// 向压缩文件中输出数据
while ((bytesRead = inputStream.read()) != -1) {
zos.write(bytesRead);
}
inputStream.close();
zos.closeEntry(); // 当前文件写完,定位为写入下一条项目
}
zos.close();
String header = req.getHeader("User-Agent").toUpperCase();
if (header.contains("MSIE") || header.contains("TRIDENT") || header.contains("EDGE")) {
fileName = URLEncoder.encode(fileName, "utf-8");
//IE下载文件名空格变+号问题
fileName = fileName.replace("+", "%20");
} else {
fileName = new String(fileName.getBytes(), "ISO8859-1");
}
response.reset();
response.setContentType("text/plain");
response.setContentType("application/octet-stream; charset=utf-8");
response.setHeader("Location", fileName);
response.setHeader("Cache-Control", "max-age=0");
response.setHeader("Content-Disposition", "attachment; filename=" + fileName);
FileInputStream fis = new FileInputStream(zipFile);
BufferedInputStream buff = new BufferedInputStream(fis);
BufferedOutputStream out = new BufferedOutputStream(response.getOutputStream());
byte[] car = new byte[1024];
int l = 0;
while (l < zipFile.length()) {
int j = buff.read(car, 0, 1024);
l += j;
out.write(car, 0, j);
}
// 关闭流
fis.close();
buff.close();
out.close();
ossClient.shutdown();
// 删除临时文件
zipFile.delete();
} catch (IOException e1) {
e1.printStackTrace();
}catch (Exception e) {
e.printStackTrace();
}
}
- 导出word
17.140 java 对数字的处理
场景:excel 导入时,会出现导入某些,可能会是文本或者数字,这样就会出现,如果是数字那么会被转成科学计数法
//验证是否为数字,如果是数字类型的防止数字被转为科学计数法类型
public static String switchNum(String str){
Boolean strResult = str.matches("-?[0-9]+.?[0-9]*[Ee]?[+-]?\\d+");
if(strResult == true) {//说明是数字
return (new BigDecimal(str)).toString();//将科学计数法转为数字
}
return str;
}
public static void main(String[] args) {
// String num="9999999999.222222";
// String num2="10";
// String num3="9.999999999222221E9";
// String num4="xxxxxx";
// System.out.println(switchNum(num));
// System.out.println(switchNum(num2));
// System.out.println(switchNum(num3));
// System.out.println(switchNum(num4));
}
- 加减乘除算法
package cn.semdo.common.utils;
import java.io.Serializable;
import java.math.BigDecimal;
import java.math.RoundingMode;
/**
* 精确计算 double and float
* Created by lxk on 2017/9/27
*/
public class DoubleUtil implements Serializable {
private static final long serialVersionUID = -3345205828566485102L;
// 默认除法运算精度
private static final Integer DEF_DIV_SCALE = 2;
/**
* 提供精确的加法运算。
*
* @param value1 被加数
* @param value2 加数
* @return 两个参数的和
*/
public static Double add(Double value1, Double value2) {
BigDecimal b1 = new BigDecimal(Double.toString(value1));
BigDecimal b2 = new BigDecimal(Double.toString(value2));
return b1.add(b2).doubleValue();
}
/**
* 提供精确的减法运算。
*
* @param value1 被减数
* @param value2 减数
* @return 两个参数的差
*/
public static double sub(Double value1, Double value2) {
BigDecimal b1 = new BigDecimal(Double.toString(value1));
BigDecimal b2 = new BigDecimal(Double.toString(value2));
return b1.subtract(b2).doubleValue();
}
/**
* 提供精确的乘法运算。
*
* @param value1 被乘数
* @param value2 乘数
* @return 两个参数的积
*/
public static Double mul(Double value1, Double value2) {
BigDecimal b1 = new BigDecimal(Double.toString(value1));
BigDecimal b2 = new BigDecimal(Double.toString(value2));
return b1.multiply(b2).doubleValue();
}
/**
* 提供(相对)精确的除法运算,当发生除不尽的情况时, 精确到小数点以后10位,以后的数字四舍五入。
*
* @param dividend 被除数
* @param divisor 除数
* @return 两个参数的商
*/
public static Double divide(Double dividend, Double divisor) {
return divide(dividend, divisor, DEF_DIV_SCALE);
}
/**
* 提供(相对)精确的除法运算。 当发生除不尽的情况时,由scale参数指定精度,以后的数字四舍五入。
*
* @param dividend 被除数
* @param divisor 除数
* @param scale 表示表示需要精确到小数点以后几位。
* @return 两个参数的商
*/
public static Double divide(Double dividend, Double divisor, Integer scale) {
if (scale < 0) {
throw new IllegalArgumentException("The scale must be a positive integer or zero");
}
BigDecimal b1 = new BigDecimal(Double.toString(dividend));
BigDecimal b2 = new BigDecimal(Double.toString(divisor));
return b1.divide(b2, scale, RoundingMode.HALF_UP).doubleValue();
}
/**
* 提供指定数值的(精确)小数位四舍五入处理。
*
* @param value 需要四舍五入的数字
* @param scale 小数点后保留几位
* @return 四舍五入后的结果
*/
public static double round(double value, int scale) {
if (scale < 0) {
throw new IllegalArgumentException("The scale must be a positive integer or zero");
}
BigDecimal b = new BigDecimal(Double.toString(value));
BigDecimal one = new BigDecimal("1");
return b.divide(one, scale, RoundingMode.HALF_UP).doubleValue();
}
//================自定义:double类型数据转为Sting ,计算返回String类型================================
/**
* 提供精确的加法运算。
*
* @param value1 被加数
* @param value2 加数
* @return 两个参数的和
*/
public static String addByStr(String value1, String value2) {
if(StringUtils.isEmpty(value1)){//如果传递的未null 则会报空指针异常
value1="0";
}
if(StringUtils.isEmpty(value2)){
value2="0";
}
BigDecimal b1 = new BigDecimal(value1);
BigDecimal b2 = new BigDecimal(value2);
return b1.add(b2).toString();
}
/**
* 提供精确的乘法运算。
*
* @param value1 被乘数
* @param value2 乘数
* @return 两个参数的积
*/
public static String mulByStr(String value1, String value2) {
if(StringUtils.isEmpty(value1)){//如果传递的未null 则会报空指针异常
value1="0";
}
if(StringUtils.isEmpty(value2)){
value2="0";
}
BigDecimal b1 = new BigDecimal(value1);
BigDecimal b2 = new BigDecimal(value2);
return b1.multiply(b2).toString();
}
//=========================验证是否为数字,如果是数字类型的防止数字被转为科学计数法类型======================================
//考虑 科学计数法的使用,将数据转为 String原样输出
public static String switchNum(String str){
//Boolean strResult = str.matches("-?[0-9]+.?[0-9]*[Ee]?[+-]?\\d+");
Boolean strResult = str.matches("[\\+\\-]?[\\d]+([\\.][\\d]*)?([Ee][+-]?[\\d]+)?");
if(strResult == true) {//说明是数字
return (new BigDecimal(str)).toString();
}
return str;
}
/* public static void main(String[] args) {
String num="9999999999.222222";
String num2="10";
String num3="9.999999999222221E9";
BigDecimal b2 = new BigDecimal(num3);
System.out.println(b2.toString()+"//======================");
System.out.println(Double.valueOf(num));
System.out.println(DoubleUtil.addByStr(num,num2));
System.out.println(DoubleUtil.mulByStr(num,num2));
System.out.println("//========================================");
System.out.println(DoubleUtil.addByStr(num3,num2));
System.out.println(DoubleUtil.mulByStr(num3,num2));
}*/
}
17.200 获取项目路径
获取项目本地决定路径到tomcat下的wabapp下对应的项目下:request.getServletContext().getRealPath("/")
17.210 转义和反转义
转义和反转义(在做文件导入的时候可能会用到,可能需要阻止其转义,例如 ± ,可能需要原样保存到数据库中 )
- 在页面中用htmlEscape="false" 来转义展示
<form:input path="rwdName" htmlEscape="false" maxlength="100" />
- StringEscapeUtils.unescapeHtml 或者HtmlUtils.htmlUnescape
导包: import org.apache.commons.lang3.StringEscapeUtils;
//导包: import org.apache.commons.lang.StringEscapeUtils;
public static void main(String[] args) {
String s = "<pre class=\"brush: java;\">";
System.out.println(StringEscapeUtils.escapeHtml(s)); =========<pre class="brush: java;">
String u = "<pre class=\"brush: java;\">";
System.out.println(StringEscapeUtils.unescapeHtml(u)); =======<pre class="brush: java;">
}
//StringEscapeUtils.unescapeHtml(u)方法写在实体类中的对应的set方法中
public void setName(String name) {
this.name = StringEscapeUtils.unescapeHtml(name);
}
- HtmlUtils.htmlUnescape
import org.springframework.web.util.HtmlUtils;
HtmlUtils.htmlUnescape() //将数据库中已经转义的还原。 例如:± 转为需要的 ±
17.220 java 包含
- List.contains();
- Collections3.extractToList(list, "savePath");
public static void main(String[] args){
List<String>list = new ArrayList<String>();
list.add("草莓"); //向列表中添加数据
list.add("香蕉"); //向列表中添加数据
list.add("菠萝"); //向列表中添加数据
for(int i=0;i<list.size();i++){ //通过循环输出列表中的内容
System.out.println(i+":"+list.get(i));
}
String o = "苹果";
System.out.println("list对象中是否包含元素"+o+":"+list.contains(o)); //判断字符串中是否包含指定字符串对象
}
17.230 linux 系统下部署 jdk
https://blog.csdn.net/qq_34021712/article/details/69816837
https://blog.csdn.net/sxdtzhaoxinguo/article/details/43731677
1.下载linux下jdk安装包jdk-7u67-linux-i586.tar.gz 2.安装步骤 第一步:创建文件夹
mkdir /usr/local/java
第二步:将下载jdk安装包,上传到该目录下 第三步:解压缩
cd /usr/local/java #进入目录
tar -zxvf jdk-7u67-linux-i586.tar.gz #解压缩
rm -rf jdk-7u67-linux-i586.tar.gz #解压缩之后删掉,节省空间
ls -l #查看一下
第四步:备份环境变量文件
cd /etc
cp profile profile_bak #如果出错误了,还可以恢复
第五步:复制路径到环境变量中 路径为:/usr/local/java/jdk1.7.0_67
编辑profile文件
# 进入编辑默认
vi /etc/profile
# 输入 i
i
# 保存或取消
esc退出 :wq 确认 q! 取消
在profile文件的末尾加入如下命令:
JAVA_HOME=/usr/local/java/jdk1.7.0_67
JRE_HOME=$JAVA_HOME/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME PATH CLASSPATH
3.测试安装是否成功 先使用命令 source /etc/profile 更新一下 再使用
java -version
17.240 cmd 命令模式下 查询进程和杀死进程
netstat -aon|findstr 5037
tasklist|findstr 21096
taskkill /f /t /im adb.exe

17.250 java 连接数据库
springboot mysql连接 https://blog.csdn.net/weixin_33901995/article/details/113326874
spring 项目 mysql 连接超时问题
https://blog.csdn.net/u013378306/article/details/80035912
spring boot项目
注意 本文针对springboot 1.3.5版本,不同版本配置会有差别
注意: 此处单为是毫秒 ms
spring boot 如果不设置spring.datasource.type,默认是使用tomcat-jdbc连接池
- 使用tomcat-jdbc在application.properties
#验证连接的有效性 此处已定要设为true,不然 time-between-eviction-runs-millis 不起作用
spring.datasource.test-while-idle=true
#获取连接时候验证,如果无效,则生成新的连接使用,会影响性能 (此处设为true最为保险,但是为影响性能)
spring.datasource.test-on-borrow=true
spring.datasource.validation-query=SELECT 1 FROM DUAL
#空闲连接回收的时间间隔,与test-while-idle一起使用,设置5分钟
spring.datasource.time-between-eviction-runs-millis=300000
#连接池空闲连接的有效时间 ,设置30分钟
spring.datasource.min-evictable-idle-time-millis=1800000
具体参数配置参看https://blog.csdn.net/u013378306/article/details/78085366
- 使用druid
注意: 此处单为是毫秒 ms
pom.xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.23</version>
</dependency>
application.properties
#druid datasouce database settings begin
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/spring_boot?characterEncoding=utf-8
spring.datasource.username=root
spring.datasource.password=123456
# 下面为连接池的补充设置,应用到上面所有数据源中
# 初始化大小,最小,最大
spring.datasource.initialSize=5
spring.datasource.minIdle=5
spring.datasource.maxActive=20
# 配置获取连接等待超时的时间
spring.datasource.maxWait=60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.timeBetweenEvictionRunsMillis=60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
spring.datasource.minEvictableIdleTimeMillis=300000
spring.datasource.validationQuery=SELECT 1 FROM DUAL
<!-- 空闲时检测,此处已定要设为true,不然 timeBetweenEvictionRunsMillis不起作用-->
spring.datasource.testWhileIdle=true
#获取连接时候验证,如果无效,则生成新的连接使用,会影响性能 (此处设为true最为保险,但是为影响性能)
spring.datasource.testOnBorrow=false
<!-- 返回给线程池时检测连接有效性 -->
spring.datasource.testOnReturn=false
# 打开PSCache,并且指定每个连接上PSCache的大小
spring.datasource.poolPreparedStatements=true
spring.datasource.maxPoolPreparedStatementPerConnectionSize=20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
spring.datasource.filters=stat,wall,log4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
spring.datasource.useGlobalDataSourceStat=true
#druid datasouce database settings end
17.270 JAVA中json转Map,jsonArray转List集合,List集合转json
https://blog.csdn.net/weixin_33446857/article/details/79171122
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.apache.commons.lang.StringUtils;
import org.zgr.pack.entity.test.TestJsonToList;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
public class Util {
//json字符串转换为MAP
public static Map jsonStrToMap(String s) {
Map map = new HashMap();
//注意这里JSONObject引入的是net.sf.json
net.sf.json.JSONObject json = net.sf.json.JSONObject.fromObject(s);
Iterator keys = json.keys();
while (keys.hasNext()) {
String key = (String) keys.next();
String value = json.get(key).toString();
if (value.startsWith("{") && value.endsWith("}")) {
map.put(key, jsonStrToMap(value));
} else {
map.put(key, value);
}
}
return map;
}
// 将jsonArray字符串转换成List集合
public static List jsonToList(String json, Class beanClass) {
if (!StringUtils.isBlank(json)) {
//这里的JSONObject引入的是 com.alibaba.fastjson.JSONObject;
return JSONObject.parseArray(json, beanClass);
} else {
return null;
}
}
//List集合转换为json
public static JSON listToJson(List list) {
JSON json=(JSON) JSON.toJSON(list);
return json;
}
public static void main(String[] args) {
System.out.println("---------------------json字符串转换为MAP---------------------");
JSONObject jsonObject=new JSONObject();
jsonObject.put("abc", 123);
jsonObject.put("def", 456);
System.out.println("A==========json====="+jsonObject);
Map map=Util.jsonStrToMap(jsonObject.toString());
System.out.println("B==========def======"+map.get("def"));
System.out.println("---------------------将jsonArray字符串转换成List集合---------------------");
String str="[{\"year\":\"2015\",\"month\":10,\"count\":47},{\"year\":2017,\"month\":12,\"count\":4}]";
//这里需要指定泛型,我们建立一个实体类TestJsonToList
List<TestJsonToList> list=Util.jsonToList(str, TestJsonToList.class);
System.out.println("C==========取list第二个元素的year====="+list.get(1).getYear());
System.out.println("---------------------将list集合转换成json---------------------");
//这里的JSONObject引入的是 com.alibaba.fastjson.JSONObject;
JSON json=Util.listToJson(list);
System.out.println("D==========json====="+json);
}
}
实体类
public class TestJsonToList {
private String year; //年
private String month; //月
private String count; //数据
public String getMonth() {
return month;
}
public void setMonth(String month) {
this.month = month;
}
public String getYear() {
return year;
}
public void setYear(String year) {
this.year = year;
}
public String getCount() {
return count;
}
public void setCount(String count) {
this.count = count;
}
//构造方法
public TestJsonToList(String year, String month, String count) {
this.year = year;
this.month = month;
this.count = count;
}
//默认构造方法
public TestJsonToList() {
}
}
json转List集合,和List集合转json时需要注意,使用的是阿里的fastJson.jar包,不要引错了,Maven项目对应引入:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.8</version>
</dependency>
java 构造JSONObject 有序添加数据
com.alibaba.fastjson.JSONObject jsonObject= new com.alibaba.fastjson.JSONObject(new LinkedHashMap());//
jsonObject.put("title","");
17.290 maven jar 冲突
https://blog.csdn.net/loongshawn/article/details/50831890
项目jar包冲突,需要找到冲突的源在哪个依赖,然后过滤掉这个依赖即可。接下来进入本地的工程目录,执行以下命令,获取依赖树:
项目根目录下执行 mvn dependency:tree
<!-- OSS Java SDK -->
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>2.2.0</version>
<exclusions> <!-- 过滤掉 aliyun-sdk-oss.jar中冲突 httpclient.jar -->
<exclusion>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</exclusion>
</exclusions>
</dependency>
19.300 阿里云OSS
https://blog.csdn.net/jklizxcqwe/article/details/103122163
待整理:阿里云OSS附件上传 https://blog.csdn.net/z1c5809145294zv/article/details/108344155
https://aliyun_portal_storage.oss.aliyuncs.com/oss_api/oss_javahtml/index.html
https://blog.csdn.net/u014559227/article/details/70888249
https://blog.csdn.net/linlin_0904/article/details/84583676
https://blog.csdn.net/fangside/article/details/113767360 //简单完整案例
https://blog.csdn.net/weixin_39507514/article/details/90799073 base64
https://blog.csdn.net/yuanyuan5201/article/details/109292046 oss压缩下载
- 需要注意的是。上传的文件名中不能有 + 号,否则无法访问 ;
- 路径不能有反斜杠,正确的 形式 proj/202104/xx.txt ,OSS会自动创建 文件夹 proj和202104
private static String BUCKETNAME="lishihuan";// Buket名称
private static String ACCESSKEYID="LTAI5t75a7pjcLnuhY4pPVyK";//AccessKey ID
private static String ACCESSKEYSECRET="NZIXJbkW7V2necehbaGVZHh9G0IrOj";//AccessKey Secret
private static String ENDPOINT="https://oss-cn-shanghai.aliyuncs.com";// 域名
private static String BUCKET_DOMAIN_URL="https://lishihuan.oss-cn-shanghai.aliyuncs.com";// EndPoint(地域节点)
//appFileHost=http://${appBucket}.${endpoint}
需要5个参数,endpoint,accessKeyId,accessKeySecret 三个用来连接OssClient客户端。bucketName 域名是用来上传数据 BUCKET_DOMAIN_URL
OSS client = new OSSClientBuilder().build(this.endpoint,this.accessKeyId,this.accessKeySecret);// 创建连接
/**
* bucketUrl 相对路径+文件名 ( proj/202104/xx.txt)
*/
client.putObject(this.bucketName, bucketUrl, new File(fileRootPath));// 上传 文件
client.shutdown();
//前端访问
String url = BUCKET_DOMAIN_URL+"/"+bucketUrl;
17.310 java 对集合的处理
整理 Collections3.java
2. 前端处理 后端方回的list集合
var listJson=${fns:toJson(list)};
Redis 作为缓存
https://blog.csdn.net/lydms/article/details/105224210
17.331 SpringBoot设置gzip压缩选项--提高数据传输速度
application.yml配置
server:
compression:
enabled: true
mime-types : text/html,text/xml,text/plain,text/css,application/javascript
- 在application.properties中添加配置信息:
#开启压缩功能
server.compression.enabled=true
#压缩数据类型
server.compression.mime-types=application/json,application/xml,text/html,text/xml,text/plain
#开启压缩最小数据字节数默认2048个字节
server.compression.min-response-size=2048
17.340 返回值 T
public static <T> T getData(String key) {
CacheData<T> data = CACHE_DATA.get(key);
// 数据未过期则返回
if (data != null && (data.getExpire() <= 0 || data.getSaveTime() >= System.currentTimeMillis())) {
return data.getData();
} else {// 数据过期则清除key
clear(key);
}
return (T) data;
}
17.450 java 使用Map 做临时缓存
https://blog.csdn.net/u012948161/article/details/103315227
https://www.cnblogs.com/dcrenl/p/14005001.html(整理:spring框架中@PostConstruct的实现原理)
@PostConstruct注解 ;项目 实例化Ben 开始执行,可以用于项目启动就搭配 全局缓存
案例:spring boot 项目,项目启动后缓存 地图数据缓存-搭配 异步 方法 执行不影响 主线程
配置:[线程](#17.471 java 线程)
配置定时器(每十分钟执行一次)
package cn.semdo.modules.job.controller;
import cn.semdo.modules.dataCenter.xjbBasGroup.dao.MapBasDao;
import cn.semdo.modules.dataCenter.xjbBasGroup.service.MapBasService;
import org.apache.commons.collections.CollectionUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
/**
* 用来更新 地图用到的 数据 缓存对象
* 每10 分钟执行一次
*/
@Component
public class MapDataUpdateCacheJob {
@Autowired
private MapBasService mapBasService;
Logger log = LoggerFactory.getLogger(MapDataUpdateCacheJob.class);
// PostConstruct 注解 本意是项目启动后执行 将地图数据缓存完成,但是 影响 主线程
@PostConstruct
public void init() {
log.info("==============开始执行地图数据缓存记录 任务开始&异步==============");
try {
mapBasService.mpDataUpdateCache();
} catch (Exception e) {
e.printStackTrace();
log.info("==============地图数据缓存 执行异常:"+e.getMessage()+"==============");
}
}
//@PreDestroy
public void destroy() {
//系统运行结束
}
@Scheduled(cron = "0 0/10 * * * ?")
public void executor() {
init();
}
}
- 业务数据
@Async
public void mpDataUpdateCache() {
long start = System.currentTimeMillis();
// 缓存线路
JSONObject lineData = createLineByType();
MemoryCacheUtils.setData("lineData2", lineData, 0);
System.out.println("线路缓存完成");
//1. 缓存GT
List<MapPointVo> towerData =mapBasDao.getTowerData(null);
MemoryCacheUtils.setData("towerData2", towerData, 0);
System.out.println("GT缓存完成");
// 2.
JSONObject skData = findSkData();
MemoryCacheUtils.setData("skData", skData, 0);
System.out.println("三跨缓存完成");
//3. 密集通道
Map<String, JSONArray> map = classifyMjtdData();
MemoryCacheUtils.setData("mjtdMap", map, 0);
System.out.println("密集通道缓存完成");
System.out.println("线程" + Thread.currentThread().getName() + " 执行异步任务:" + DateUtils.getDateTime());
long end = System.currentTimeMillis();
System.out.println("任务全部完成,总耗时:" + (end - start) + "毫秒");
log.info("==============地图数据缓存 执行完成==============");
}
17.470
public Future<String> doTaskOne() throws Exception {
System.out.println("开始做任务一");
long start = System.currentTimeMillis();
Thread.sleep(random.nextInt(10000));
long end = System.currentTimeMillis();
System.out.println("完成任务一,耗时:" + (end - start) + "毫秒");
return new AsyncResult<>("任务一完成");
}
17.471 java 线程
https://blog.csdn.net/asd136912/article/details/87716215
package cn.semdo.config;
import org.springframework.aop.interceptor.AsyncUncaughtExceptionHandler;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.AsyncConfigurer;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
@Configuration
@EnableAsync
public class AsyncTaskConfig implements AsyncConfigurer {
// ThredPoolTaskExcutor的处理流程
// 当池子大小小于corePoolSize,就新建线程,并处理请求
// 当池子大小等于corePoolSize,把请求放入workQueue中,池子里的空闲线程就去workQueue中取任务并处理
// 当workQueue放不下任务时,就新建线程入池,并处理请求,如果池子大小撑到了maximumPoolSize,就用RejectedExecutionHandler来做拒绝处理
// 当池子的线程数大于corePoolSize时,多余的线程会等待keepAliveTime长时间,如果无请求可处理就自行销毁
@Override
@Bean
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor threadPool = new ThreadPoolTaskExecutor();
//设置核心线程数
threadPool.setCorePoolSize(10);
//设置最大线程数
threadPool.setMaxPoolSize(100);
//线程池所使用的缓冲队列
threadPool.setQueueCapacity(10);
//等待任务在关机时完成--表明等待所有线程执行完
threadPool.setWaitForTasksToCompleteOnShutdown(true);
// 等待时间 (默认为0,此时立即停止),并没等待xx秒后强制停止
threadPool.setAwaitTerminationSeconds(60);
// 线程名称前缀
threadPool.setThreadNamePrefix("Derry-Async-");
// 初始化线程
threadPool.initialize();
return threadPool;
}
@Override
public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() {
return null;
}
}
17.470 java 利用map 分组
public JSONObject createGeoJSONForPointByType(List<MapPointVo> queryList){
// 数据分组
Map<String, List<MapPointVo>> groupMap= Maps.newHashMap();
for (MapPointVo mapPointVo : queryList) {
String key = mapPointVo.getSubType();
//============containsKey是用来判断某个key是否存在
if(!groupMap.containsKey(key)){ //=====不存在就新new一个map对象,并将此时的设备名称作为key存入。
groupMap.put(key, Lists.newArrayList());
}
groupMap.get(key).add(mapPointVo);
}
JSONObject GeoJSONMap = new JSONObject();
for (String key : groupMap.keySet()) {
List<MapPointVo> groupArr = groupMap.get(key);
GeoJSONMap.put(key,createGeoJSONForPoint(groupArr));
}
return GeoJSONMap;
}
java 合集工具类
Collections3
SpringBoot返回结果如果为null或空值不显示处理方法
https://blog.csdn.net/lihua5419/article/details/81223045
https://blog.csdn.net/weixin_43969830/article/details/103203986
https://www.cnblogs.com/qinxu/p/10208858.html
第一种方法:在application.yml配置文件中
spring:
jackson:
default-property-inclusion: non_null
第二种:新建配置类:(去掉 null 或 "" 字段)
package com.zpark.tools;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.http.converter.json.Jackson2ObjectMapperBuilder;
/**
* @author cosmo
* @Title: JacksonConfig
* @ProjectName
* @Description:
* @date
*/
@Configuration
public class JacksonConfig {
@Bean
@Primary
@ConditionalOnMissingBean(ObjectMapper.class)
public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) {
ObjectMapper objectMapper = builder.createXmlMapper(false).build();
//通过该方法对mapper对象进行设置,所有序列化的对象都将按改规则进行系列化,属性为NULL 不序列化
objectMapper.setSerializationInclusion(JsonInclude.Include.NON_NULL);
return objectMapper;
} //Include.Include.ALWAYS 默认 //Include.NON_DEFAULT 属性为默认值不序列化 //nclude.NON_EMPTY 属性为 空("") 或者为 NULL 都不序列化 //Include.NON_NULL 属性为NULL 不序列化
}
替换非空:
public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) {
ObjectMapper objectMapper = builder.createXmlMapper(false).build();
objectMapper.getSerializerProvider().setNullValueSerializer(new JsonSerializer<Object>() {
@Override
public void serialize(Object o, JsonGenerator jsonGenerator,SerializerProvider serializerProvider)throws IOException, JsonProcessingException {
jsonGenerator.writeString("");
}
});
return objectMapper;
}
17.480 Springboot读取本地json文件

- 导入依赖
<!-- json-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.49</version>
</dependency>
<!-- io-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
- 读取
File jsonFile = ResourceUtils.getFile("classpath:static/publicfile/yjxmb.json");
//将json转化为String
String json = FileUtils.readFileToString(jsonFile);
JSONArray jsonArray = JSON.parseArray(json);//alibaba
14.490 对象赋值(内部类)
final String userId=planConfigUser.getUserId();
planConfigUser.setUser(new User(){
{
setId(userId);
}
});
14.500 升级为1.7后, 静态文件包含中文请求不到
https://blog.csdn.net/dongyan3595/article/details/118577368shiro
14.510 java 对JSON 处理
net.sf.json.JSONException: Object is null 如果返回的字段中含有 null, 则会报错, 通过nvl(xx,'') 也不行 需要讲jar 换为 com.alibaba.fastjson
1. FastJson 对json中的KEY值的大小写转换方法
/**
* json大写转小写
*
* @return JSONObject
*/
public static JSONObject transToLowerObject(String json) {
JSONObject JSONObject2 = new JSONObject();
JSONObject JSONObject1 = JSON.parseObject(json);
for (String key : JSONObject1.keySet()){
Object object = JSONObject1.get(key);
if (object.getClass().toString().endsWith("JSONObject")) {
JSONObject2.put(key.toLowerCase(), transToLowerObject(object.toString()));
} else if (object.getClass().toString().endsWith("JSONArray")) {
JSONObject2.put(key.toLowerCase(), transToArray(JSONObject1.getJSONArray(key).toString()));
}else{
JSONObject2.put(key.toLowerCase(), object);
}
}
return JSONObject2;
}
/**
* jsonArray转jsonArray
*
* @return JSONArray
*/
public static JSONArray transToArray(String jsonArray) {
JSONArray jSONArray2 = new JSONArray();
JSONArray jSONArray1 = JSON.parseArray(jsonArray);
for (int i = 0; i < jSONArray1.size(); i++) {
Object jArray = jSONArray1.getJSONObject(i);
if (jArray.getClass().toString().endsWith("JSONObject")) {
jSONArray2.add(transToLowerObject( jArray.toString()));
} else if (jArray.getClass().toString().endsWith("JSONArray")) {
jSONArray2.add(transToArray(jArray.toString()));
}
}
return jSONArray2;
}
这是递归方法,JSONArray用下面的方法,JSONObject用上面的方法
还有这种方案
/**
* json的Key值转化为小写
* @param json
* @return
*/
public static String transformLowerCase(String json){
String regex = "[\\\"' ]*[^:\\\"' ]*[\\\"' ]*:";// (\{|\,)[a-zA-Z0-9_]+:
Pattern pattern = Pattern.compile(regex);
StringBuffer sb = new StringBuffer();
// 方法二:正则替换
Matcher m = pattern.matcher(json);
while (m.find()) {
m.appendReplacement(sb, m.group().toLowerCase());
}
m.appendTail(sb);
return sb.toString();
}
14.550 异常记录
1. 保存数据到
15.560 Java中List集合去重的几种方式
// 准备数据
List<String> list = new ArrayList();
list.add("a");
list.add("b");
list.add("c");
list.add("c");
list.add("b");
list.add("a");
1. 利用HashSet去重
// 利用list中的元素创建HashSet集合,此时set中进行了去重操作
HashSet set = new HashSet(list);
// 清空list集合
list.clear();
// 将去重后的元素重新添加到list中
list.addAll(set);
2. 通过List的contains()方法去重( 该方法 在平时用的最多)
// 创建一个新的list集合,用于存储去重后的元素
List listTemp = new ArrayList();
// 遍历list集合
for (int i = 0; i < list.size(); i++) {
// 判断listTemp集合中是否包含list中的元素
if (!listTemp.contains(list.get(i))) {
// 将未包含的元素添加进listTemp集合中
listTemp.add(list.get(i));
}
}
3. 循环List进行去重
// 从list中索引为0开始往后遍历
for (int i = 0; i < list.size() - 1; i++) {
// 从list中索引为 list.size()-1 开始往前遍历
for (int j = list.size() - 1; j > i; j--) {
// 进行比较
if (list.get(j).equals(list.get(i))) {
// 去重
list.remove(j);
}
}
}
按理 对 方法2
场景:消息推送,需要考虑当前人员是否已经推送过,
public void send(){
List<SysEmp> receiveList=new ArrayList<>();
List userLististTemp = new ArrayList();// 用来去重
for (SysPushModulesContent s1 : positiveContents) {
// 业务处理
List<SysPushSendRef> refList = sysPushSendRefPackageForEmp(id,receiveList,userLististTemp);
}
}
/**
组装 消息推送 sysPushSendRef 记录
userLististTemp:用来控制是否已经推送过
*/
public List<SysPushSendRef> sysPushSendRefPackageForEmp(String objId,List<SysEmp> empList,List userLististTemp){
if(empList==null || empList.size()==0){//表示没有对指定角色分配用户
return null;
}
List<SysPushSendRef> refList= Lists.newArrayList();//作为最后 存放接收人的 参数
for (SysEmp sysEmp : empList) {//定义 消息发送 人员信息(消息发送表)——————指定接收人信息
if(sysEmp!=null&& sysEmp.getPushId()!=null){
if (!userLististTemp.contains(sysEmp.getId())) {// 用于判断是否推送过
SysPushSendRef ref =new SysPushSendRef();
ref.setPushId(sysEmp.getPushId());
ref.setReceive(sysEmp.getId());// 接收人id
// 业务处理
refList.add(ref);
userLististTemp.add(sysEmp.getId());
}
}
}
if(refList==null || refList.size()==0){//表示没有对指定角色分配用户
return null;
}
return refList;
}
tomcat 下载
官网 : https://tomcat.apache.org/download-80.cgi#8.5.73
教程:https://www.cnblogs.com/li150dan/p/12535067.html
15.570 spring的 InitializingBean 的 afterPropertiesSet 来初始化
https://www.cnblogs.com/feiyun126/p/7685312.html
15.580 java 对16 进制的处理
16进制转10进制
String string = "000002af";
System.out.print(Long.valueOf(string,16));//--> 687
对于温度的处理,一般是 16进制补码转
/**
* 16进制补码转10进制数
* @param str
* @return
*/
public static int complemwnt(String str) {
int result = 0;
String binaryString = Integer.toBinaryString(Integer.valueOf(str, 16));
while(binaryString.length() < 16){
binaryString = "0"+binaryString;
}
String binary = binaryString.substring(0,1);//取第一位判断正负
if ("0".equals(binary)) {
result = Integer.valueOf(binaryString,2);
}else {
String[] split = binaryString.split("");
StringBuilder builder = new StringBuilder();
for (String s : split) {
if("0".equals(s)){
builder.append("1");
}else {
builder.append("0");
}
}
// 调用Integer.valueOf(value, 2) 将二进制转为十进制.
result = Integer.valueOf(builder.toString(),2);
// 先取负数在减1
result = (0 - result) - 1;
}
return result;
}
计算工具:https://www.23bei.com/tool-56.html
列如:0000ff9b代表-101

运行jar 包项目
项目打包jar
## cmd 到目录下
java -jar test2-0.0.1-SNAPSHOT.jar
java -jar test2-0.0.1-SNAPSHOT.jar --server.port=8082

17.590 java 对时间的处理
格式化时间
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
java list 循环覆盖
import org.springframework.beans.BeanUtils;
BeanUtils.copyProperties("转换前的类", "转换后的类");
for (PushMessage pushMessage : list) {
// 从缓存中获取数据,个人最新消息 和 个人未读消息个数
String key = "mess:latestNews:"+receiveId+":"+pushMessage.getPid();
boolean exist = redisService.exist(key);
if(exist){
//pushMessage = getPushMessage(key);// 这样覆盖,不会对list产生影响,也即覆盖没有生效
BeanUtils.copyProperties(getPushMessage(key),pushMessage);// 通过拷贝复制对象,覆盖原对象
}
按照时间倒叙排列,没有时间放最后
private void sortPushMessList(List<PushMessage> list) {
Collections.sort(list, new Comparator<PushMessage>() {
@Override
public int compare(PushMessage pushMessage1, PushMessage pushMessage2) {
if(pushMessage1.getSendTime()==null&&pushMessage2.getSendTime()!=null){
return 1;
}
if(pushMessage1.getSendTime()==null&&pushMessage2.getSendTime()==null){
return -1;
}
if(pushMessage1.getSendTime()!=null&&pushMessage2.getSendTime()==null){
return -1;
}
int flag = pushMessage2.getSendTime().compareTo(pushMessage1.getSendTime());
return flag;
}
});
}
判断Object对象为空或空字符串
/**
* 判断Object对象为空或空字符串
* @param obj
* @return
*/
public static Boolean isObjectNotEmpty(Object obj) {
String str = ObjectUtils.toString(obj, "");
Boolean flag = StringUtils.isNotBlank(str);
return flag;
}
JSONObject对象与JSON转换
参考:https://blog.csdn.net/qq_32138419/article/details/123796365
com.alibaba.fastjson.JSONObject之对象与JSON转换方法
输出:{name=大道,age=2,sex=m} -->
Student stu = new Student("大道", "m", 2);
//Java对象转换成JSON字符串
String stuString = JSONObject.toJSONString(stu);//{"age":2,"name":"大道","sex":"m"}
附件上传
同下面的 附属表重复添加 删除用户删除附件,找到新增的执行批量添加
/**
* 保存附件
* 1. 需要找到用户删除的记录,执行删除
* 2. 拿到新增的附件,执行批量添加
* @param wlWorkOpRec
*/
@Override
public void saveFilesByRec(WlWorkOpRec wlWorkOpRec) {
SysUser currUser = utils.getSysUser();
// 1. 找到用户删除的记录,在数据库中删除
if(wlWorkOpRec.getId()!=null){ // 只有更新时才会有 历史上传的附件记录,从而需要去执行删除
List<Long> existFileIdList = wlWorkOpRec.getWlWorkOpFilesList().stream()
.filter(wlWorkOpFiles -> wlWorkOpFiles.getId() != null)
.map(WlWorkOpFiles::getId)
.collect(Collectors.toList()); // 获取之前上传的记录,主要是用于删除用户已经删除的记录
// 删除附件,如果existFileIdList支持为空(全部删除)
wlWorkOpFilesMapper.deleteOpFilesByOPidAndFileids(wlWorkOpRec.getId(),existFileIdList);
}
// 2. 拿到新增的数据,进行批量添加
List<WlWorkOpFiles> addFiles = Lists.newArrayList();
// wlWorkOpRec.getWlWorkOpFilesList().stream()
// .filter(wlWorkOpFiles -> wlWorkOpFiles.getId() == null)
// .collect(Collectors.toList());
AtomicInteger index = new AtomicInteger();
wlWorkOpRec.getWlWorkOpFilesList().forEach(wlWorkOpFiles->{
if(wlWorkOpFiles.getId()==null){
completeFile(wlWorkOpFiles,currUser,wlWorkOpRec.getId(), index.getAndIncrement());
addFiles.add(wlWorkOpFiles);
}
});
if(addFiles!=null && addFiles.size()>0){
wlWorkOpFilesMapper.batchInsert(addFiles);
}
}
public void completeFile(WlWorkOpFiles wlWorkOpFiles,SysUser currUser,Long opId,int index){
wlWorkOpFiles.setOpId(opId);
wlWorkOpFiles.setUploaderId(currUser.getUserId());
wlWorkOpFiles.setUploaderName(currUser.getNickName());
wlWorkOpFiles.setUploadTime(DateUtils.getNowDate());
wlWorkOpFiles.setOrderNum(index);
wlWorkOpFiles.setFileType(FileUtils.getFileType(wlWorkOpFiles.getFilePath()));
}
执行删除,通过<if test="fileIdList != null and fileIdList.size()" > 可以支持全部删除
<delete id="deleteOpFilesByOPidAndFileids" >
delete from wl_work_op_files
where OP_ID = #{opId}
<if test="fileIdList != null and fileIdList.size()" >
and id not in
<foreach item="fileId" collection="fileIdList" open="(" separator="," close=")">
#{fileId}
</foreach>
</if>
</delete>
附属表重复添加
场景:附件表因为每次保存都会重复添加记录,又不能删除后重新添加,所以做法是,先删除数据库中已经给用户删除的记录,然后剔除数据库中存在的,再执行批量保存
- 思路:
<!-- 1. 删除多余的附件-->
<delete id="deleteNotExistFilePath" >
delete from base_file
where 业务主表id=#{业务主表id}
and file_path not in
<foreach item="fileItem" collection="fileList" open="(" separator="," close=")">
#{fileItem.filePath}
</foreach>
</delete>
2. 去掉数据库现有的记录(拿到新增的)
循环 取没有id的记录-即为新增
3. 执行批量保存 新增的
// 1. 保存前 删除多余的附件
dsQuestionImgMapper.deleteNotExistFilePath(dsLocId,relativePathList);
// 2. 剔除,数据库存在的记录(主要是找到 新增的记录)
relativePathList.removeAll(dsQuestionImgMapper.getExistFilePath(dsLocId,relativePathList));
if (relativePathList == null || relativePathList.size() == 0) {
return;
}
// 3. 组装数据,批量保存
List<DsQuestionImg> dsQuestionFilesList = Lists.newArrayList();
//..... 业务处理
dsQuestionImgMapper.batchInsert(dsQuestionFilesList, dsLocationRecord);// 批量插入 隐患上报文件
<!-- 找到已经存在的 -->
<select id="getExistFilePath" resultType="string">
select file_path from ds_question_img
where ds_loc_id=#{dsLocId}
and file_path in
<foreach item="relativePath" collection="relativePathList" open="(" separator="," close=")">
#{relativePath}
</foreach>
</select>
<!--删除多余的附件-->
<delete id="deleteNotExistFilePath" >
delete from ds_question_img
where ds_loc_id=#{dsLocId}
and file_path not in
<foreach item="relativePath" collection="relativePathList" open="(" separator="," close=")">
#{relativePath}
</foreach>
</delete>
<insert id="batchInsert">
insert into ds_question_img(
ds_loc_id, file_type, upload_time, uploader_id, uploader_name, file_name, file_path, remark)
values
<foreach collection="dsQuestionImgList" separator="," item="item">
(
#{dsLocationRecord.id},#{item.fileType},#{item.uploadTime},#{item.uploaderId},#{item.uploaderName},
#{item.fileName},#{item.filePath},null
)
</foreach>
</insert>
Java 8 中的流式操作
要获取
id为空的记录并重新组成一个新的 List
List<ZjjcTestPic> zjjcTestPicList = zjjcTestJz.getTestPicList().stream().filter(pic -> pic.getId() == null)
.collect(Collectors.toList());
这个方法叫做 Java 8 中的流式操作(Stream API)中的 filter() 方法。filter() 方法用于根据指定的条件过滤流中的元素,并返回满足条件的元素组成的新流。
在给定的示例代码中,我们使用了 filter() 方法来过滤 List<ZjjcTestPic> 数组中的元素,根据条件筛选出 id 为空的记录。
流式操作是 Java 8 引入的一种函数式编程风格的处理集合数据的方式。通过使用流式操作,您可以以更简洁、更可读的方式对集合进行操作,例如过滤、映射、排序等。filter() 方法是 Stream API 中最常用的一个方法之一,它接受一个 Predicate 函数式接口作为参数,并返回一个新的流,其中包含符合条件的元素。
除了 filter() 方法外,Stream API 还提供了许多其他常用的方法,例如 map()、collect()、forEach() 等,可以根据需求进行链式调用,以实现复杂的集合操作。
java8流式操作
身份证规则

javaBean 复制
现有的对象 sysUser 是有数据的,因为保存用到的对象是SysUserVO ,所以通过 BeanUtils.copyProperties 进行复制
SysUserVO sysuservo=new SysUserVO();
BeanUtils.copyProperties(sysUser,sysuservo); // sysUser ==> sysuservo
前端发送 json数据,后端不用实体对象接受
@PostMapping("/getLineDeatil")
public AjaxResult getLineDeatil(@RequestBody String queryParam){
try {
JSONObject jsonObject = JSONObject.parseObject(queryParam);
return AjaxResult.success(mapDetailService.getLineDeatil(jsonObject));
} catch (Exception e) {
e.printStackTrace();
return AjaxResult.error(e.getMessage());
}
}
//dao层
/**
* 线路途经的YJ站(包含起点终点)
* @param jsonObject
* @return
*/
List<Map<String, Object>> wayPointForTeam(JSONObject jsonObject);
案例
选择线路+' '+ GT
@Override
public List<Map<String, Object>> getNearBasTowerList(BasTower basTower) {
// 专门用于模糊匹配 线路+' '+ GT 拆字
if(basTower.getInputSearch()!=null && !"".equals(basTower.getInputSearch())){
String[] inputSearchArr = basTower.getInputSearch().split(" ");
if(inputSearchArr!=null && inputSearchArr.length>1){
String[] arr = getInputSearch(inputSearchArr);// 防止 空格过多
basTower.setInputSearch(arr[0]);
basTower.setInputSearch2(arr[1]);
}
}
return basTowerMapper.getNearBasTowerList(basTower);
}
// 考虑 basTower.getInputSearch().split(" ") 之后 肯能出现 很多空格,要从所有空格中剔除
public String[] getInputSearch(String[] toEmailArray){
//1.将内部类的array变成util的array
List<String> toEmailList = new ArrayList( Arrays.asList(toEmailArray));
Iterator<String> iterator = toEmailList.iterator();
while (iterator.hasNext()) {
String str = iterator.next();
if ("".equals(str)) {
iterator.remove(); //2.注意这个地方
}
}
//toEmailArray = toEmailList.toArray(new String[0]); //将list转为string[]
return toEmailList.toArray(new String[toEmailList.size()]);
}
<if test="inputSearch != null and inputSearch != '' and (inputSearch2 == null or inputSearch2 == '')">
and(bt.line_name like concat('%', #{inputSearch}, '%') or bt.TOWER_NAME like concat('%', #{inputSearch}, '%') )
</if>
<if test="inputSearch != null and inputSearch != '' and inputSearch2 != null and inputSearch2 != ''">
and(bt.line_name like concat('%', #{inputSearch}, '%') and bt.TOWER_NAME like concat('%', #{inputSearch2}, '%') )
</if>
java 反射
/**
* 以类的属性的get方法方法形式获取值
* @param o:实体对象
* @param field: 字段名称
*/
private Object getValue(Object o, String field) throws Exception
{
if (StringUtils.isNotEmpty(name))
{
Class<?> clazz = o.getClass();
String methodName = "get" + name.substring(0, 1).toUpperCase() + name.substring(1);
Method method = clazz.getMethod(methodName);
o = method.invoke(o);
}
return o;
}
// getValue(basFsFhss,"bqArea")
private String getProperty(ZjjcMaterialInfo item, String fieldName) {
try {
Method method = item.getClass().getMethod("get" + StringUtils.capitalize(fieldName));
return (String) method.invoke(item);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
excel 导入 对时间的校验,赋值
1. 想实现的效果 item.setBdCreateTime(getDate(item.getBdCreateTimeStr(),"便桥修建日期",dataDescribe,sdf)); // dataDescribe 校验结果,但是 基础类型的字段无法传递,导致 dataDescribe 无法记录 校验结果
调用: dataDescribe += ExcelImportVerification.validationDate(item.getBqCreateTimeStr(),"setBqCreateTime",item,"便桥修建日期" ,sdf);
/**
* 对时间校验,并且实现赋值
* @param datestr: 日期字符串
* @param field:需要赋值的日期字段名称
* @param obj: 实体对象
* @param tips:提示
* @param sdf:格式化日期 SimpleDateFormat 对象
* @return : 返回 校验结果
*/
public static String validationDate(String datestr,String field,Object obj,String tips, SimpleDateFormat sdf){
if (StringUtils.isNotBlank(datestr)) {
try {
Method method = obj.getClass().getMethod(field, Date.class);
method.invoke(obj , sdf.parse(datestr));
} catch (Exception e) {
e.printStackTrace();
return tips+ "格式不正确;";
}
}
return "";
}
字符串长度
// 1.通过String的 length() 方法
String str = "ABCDEFGhijklmn";
System.out.println(str.length());//空格也算一个字符,,这样实际是不准确的,但是可以和前端的限定保持一致
// 2. 通过String的 getBytes,不建议使用
str.getBytes().length
严格计算 长度,中文2个字符
/**
* 获取字符串的长度,如果有中文,则每个中文字符计为2位
* @param value
* 指定的字符串
* @return 字符串的长度
*/
public static int length(String value) {
int valueLength = 0;
String chinese = "[\u0391-\uFFE5]";
/* 获取字段值的长度,如果含中文字符,则每个中文字符长度为2,否则为1 */
for (int i = 0; i < value.length(); i++) {
/* 获取一个字符 */
String temp = value.substring(i, i + 1);
/* 判断是否为中文字符 */
if (temp.matches(chinese)) {
/* 中文字符长度为2 */
valueLength += 2;
} else {
/* 其他字符长度为1 */
valueLength += 1;
}
}
return valueLength;
}
导入导出对数字的校验
/**
* 小数位数限定
*
* @param str : 数值
* @param format:指定格式 小数或者整数 "8,4"|| "8"
* @return
*/
public static boolean checkDigit(String str, String format) {
String[] formatArr = format.split(",");
if (formatArr.length == 1) { // 说明当前校验的是整数
if (str.length() > Integer.valueOf(formatArr[0])) {
return false;
} else {
return true;
}
}
String patternStr = "^(\\d){1," + formatArr[0] + "}(\\.(\\d){0," + formatArr[1] + "})?$";
final Pattern pattern = Pattern.compile(patternStr);
Matcher match = pattern.matcher(str);
return match.matches();
}
/**
* 验证 小数/整数 长度 类型字段的长度
* @param integerField :需要校验的数值
* @param format:指定格式 小数或者整数 "8,4"|| "8"
* @param tips:提示信息
*/
public static String validationNumLength(Object integerField, String format, String tips) {
if (integerField != null) {
if (!checkDigit(integerField.toString(), format)) {
return tips + "过长;";
}
}
return "";
}
// 调用 validationNumLength(item.getBdWidth(),"8,4", "便道宽度")
使用JSONObject作为实体对象
@RequestMapping(value = "findLineData2", method = RequestMethod.POST)
public AjaxResult findLineData2(@RequestBody String queryParam){
try {
JSONObject jsonObject = JSONObject.parseObject(queryParam);
return AjaxResult.success(mapBasService.findLineData2(jsonObject));
} catch (Exception e) {
e.printStackTrace();
return AjaxResult.error(e.getMessage());
}
}
<select id="findQxYhData" resultType="cn.semdo.ydxjdbapi.domain.MapPointVo">
select * from (
SELECT yh.id,'' as name, 'yh' as type,
ifnull(if(length(trim(YH_LOC_JD_GB))>0,YH_LOC_JD_GB,null),longitude_GB) lng,
ifnull(if(length(trim(YH_LOC_WD_GB))>0,YH_LOC_WD_GB,null),latitude_GB) lat,
CONCAT('yh',yh.YH_LEVEL_MANAGE) subType
FROM yh_op_record yh,bas_tower t
WHERE yh.S_TOWER_ID=t.id
<if test="opTeamId!=null and opTeamId != ''">
AND yh.op_team_id = #{opTeamId}
</if>
<if test="opOrgId!=null and opOrgId != ''">
AND yh.op_org_id = #{opOrgId}
</if>
union all
select qx.id,'' as name, 'qx' as type, longitude_gb lng, latitude_gb lat,
CONCAT('qx',QX_LEVEL) as subType
FROM qx_op_record qx,bas_tower t
WHERE qx.TOWER_ID=t.id
<if test="opTeamId!=null and opTeamId != ''">
AND qx.op_team_id = #{opTeamId}
</if>
<if test="opOrgId!=null and opOrgId != ''">
AND qx.op_org_id = #{opOrgId}
</if>
)aa
order by type,subType
</select>
64工作流
工作流驳回,获取上一个节点的操作人
/**
** 获取上个节点的 操作人
** @param objId :业务表id
** @param procInsId:流程id
** @param taskDefKey:流程标识(上个流程节点的流程标识)
** @param defaultUserId:如果没有找到 指定的人,返回该字段,防止返回空数据*
** @return
**/
public String getActMesByTaskDefKey(String objId,String procInsId,String taskDefKey,String defaultUserId){
// List<Map<String, Object>> list = histoicFlowList(objId,procInsId);
// Map<String, Object> map = Maps.newHashMap();
// for (Map<String, Object> histoicFlow:list ) {
// if(histoicFlow.get("taskDefKey").equals(taskDefKey)){
// map.put(taskDefKey, histoicFlow);
// }
// }
String userid=defaultUserId;
List<HistoricActivityInstance> list = historyService
.createHistoricActivityInstanceQuery()
.processInstanceId(procInsId).activityId(taskDefKey)
.orderByHistoricActivityInstanceStartTime().asc()
.orderByHistoricActivityInstanceEndTime().asc().list();
if(list!=null && list.size()>0 ){
HistoricActivityInstance historicActivityInstance = list.get(list.size() - 1);
if(historicActivityInstance!=null && !"".equals(historicActivityInstance)){
return historicActivityInstance.getAssignee();
}
}
return userid;
}
待整理 获取连线名称
删除任务
/**
* 工作流删除任务
*
* @param procInsId:流程实例id
* @param describe:说明
*/
@Override
public void deleteProcessInstance(String procInsId, String describe) {
// 删除流程实例
runtimeService.deleteProcessInstance(procInsId, "删除");
// 删除历史记录
historyService.deleteHistoricProcessInstance(procInsId);
}
java 校验密码
66 接口
百度接口 通过百度坐标获取当前位置详情
//通过坐标获取位置详情
http://api.map.baidu.com/geocoder/v2/?ak=rCTTTEXWsRNW3AlNvDbO2Bc5&location=31.940524127201048,117.27147584517168&output=json
//获取城市行政规划边界坐标点(用法查看 arcgis笔记中)
https://api.map.baidu.com/getscript
天气
http://apis.baidu.com/heweather/weather/free
https://lbs.amap.com/api/webservice/guide/api/weatherinfo/
http://restapi.amap.com/v3/weather/weatherInfo
tomcat
修改tomcat 其他cmd的窗口标题
修改 catalina.bat 中的 338行 if "%TITLE%" == "" set TITLE=带电库房物质系统
注: cmd 下 chcp 如果查询出来的是 936 则表示cmd是gbk编码,这时如果先标题不乱码可以先修改 catalina.bat 编码为 GBK2312 或者直接改为 ANSI
tomcat 日志乱码【不是指项目】
启动的cmd窗口中文乱码
只改 logging.properties 修改 java.util.logging.ConsoleHandler.encoding = GBK
100 其他
100.1 PDM 备注列不显示

设置样式
右击表,然后 获取格式,在对需要修改的表上,右击选中 应用格式,从而实现样式的复用

字段显示设置
空白区域右击选择
显示首选项然后进入选择table,table列有两个tab,一个是设置显示的字段,一个是设置字体格式,这步操作完后,就可以通过上面的复制/应用格式 功能
- 目前显示五列
- 第一列:显示中文Name
- 第二列:显示英文Code
- 第三列:显示Data Type(字段类型和长度 例如:bigint(20))
- 第四列:Key Indicator/Index Indicator
- 第五列:Null Status
设置字体大小,外键和主键颜色
同上步,进入 table/format 设置
- 先设置默认字体大小和颜色:微软雅黑8号黑色
- 设置主键:红色
- 设置外键:蓝色
- 设置通用字段
- 主键
- 外键
100.2 svn
.idea classes target *iml *.o *.lo *.la *.al .libs *.so *.so.[0-9]* *.a *.pyc *.pyo __pycache__ *.rej *~ #*# .#* .*.swp .DS_Store [Tt]humbs.db
MyEclipse 代码提交时,让svn忽略classpath、target、.project //https://blog.csdn.net/xiaojin21cen/article/details/83054820
Svn 设置文件忽略
100.3 idea 启动报错
Error running 'SdbdApplication':
Command line is too long. Shorten command line for SdbdApplication or also for Spring Boot default configuration.

100.4 端口
## 查询所有进程
netstat -ano
## 查询指定端口是否被占
netstat -ano | findstr "8215"
# 或者
netstat -ano | findstr :9205
## 查看进程号 3736 是哪个程序 占用在
tasklist | findstr "3736"
## 结束该进程
taskkill /f /t /im java.exe
taskkill /F /PID 31356
## 杀死 指定进程号 (linux)
kill -9 端口号
C:\Users\lishihuan>netstat -ano | findstr "8081"
TCP 0.0.0.0:8081 0.0.0.0:0 LISTENING 1296
TCP [::]:8081 [::]:0 LISTENING 1296
C:\Users\lishihuan>tasklist | findstr "1296"
java.exe 1296 Console 17 1,724,040 K